Redis入门
实用主义的redis学习日志,使用的资料为《Redis实战》
简介
Redis是一个速度非常快的非关系型数据库,可以存储键与5种不同类型的值,可以将存储在内存的键值持久化到硬盘,可以使用复制特性来扩展读性能,还可以使用客户端分片来扩展写性能。
数据结构
redis有五种数据结构:String, List, Set, Hash, ZSet(有序集合)
| 结构类型 | 结构存储的值 | 结构的读写能力 |
|---|---|---|
| string | 字符串,整数或浮点数 | 对整个字符串或字符串的一部分执行操作,可以对数字类型执行增减操作 |
| list | 一个链表,每个结点都包含一个字符串 | 从链表的两端推入或弹出元素,根据偏移量对链表进行修剪;读取单个或多个元素,根据值查找或移除元素 |
| set | 包含字符串的无序收集器 | 添加,获取,移除单个元素;检查一个元素是否存在;计算并交叉 |
| hash | 包含键值对的无序列表 | 添加,获取单个键值对,获取所有键值对 |
| zset | 字符串成员与浮点数分值(score)之间的有序映射,元素的排列由分值决定 | 添加,获取,删除单个元素;根据分值范围获取元素。 |
在Redis中存储的基本思路:键名称为 xx:id, 冒号前表明这组数据属于的实体类,冒号之后用于分割实体类对应的不同对象(如果需要的话)。值使用的数据结构则要根据实际情况判断,例如hash适用于存储对象中字段和对应的值;set适用于需要去重/并交叉运算的情况;zset可以用于需要排序的情况。
一些例子.


Redis在Web中的应用
管理用户登录会话
每一个web服务都会使用cookie来记录访客的身份,并要求浏览器存储这些数据,在下一次登录时携带这些数据。
| cookie类型 | 优点 | 缺点 |
|---|---|---|
| 签名cookie | 验证cookie需要的一切信息都存储在cookie里,cookie也可以包含额外的信息,并且对这些信息签名也很容易 | 正确处理签名很困难,容易造成安全漏洞 |
| 令牌cookie | 添加信息非常容易。cookie体积非常小,可以有效提升访问速度 | 需要在服务器中存储更多数据,用关系型数据库存储会带来较大的开销。 |
下面假设一个场景:假如我们希望记录用户最近浏览的内容,由于这类数据一般都有微量,不定期的特质,如果使用关系型数据库会导致大量细碎的IO,严重拖慢运行速率。但是使用redis的话就可以有效解决在效率上的问题,但是内存的大小也同样不是无限的,因此我们需要定期对数据进行修剪。
def update_token(conn, token, user, item=None):
timestamp = time.time()
conn.hset('login:', token, user) # 维护用户和令牌的映射关系
conn.zadd('recent:', token, timestamp) # 记录token最后一次使用时间
if item:
conn.zadd('viewed:' + token, item, timestamp) # 添加最近浏览的商品
conn.zremrangebyrank('viewed:' + token, 0, -26) # 移除旧的记录,只保留最近的25个只在服务端维持指定数量的token,每隔一段时间检查token数是否超标,如果超过阈值就将最老的token删除。
这里会存在一个竞争问题,如果要删除的token正在进行操作就会导致用户在操作中途被要求重新登陆。
QUIT = False
LIMIT = 1000000
def clean_session(conn):
while not QUIT:
size = conn.zcard('recent:')
if size <= LIMIT:
time.sleep(1)
continue
end_index = min(size - LIMIT, 100)
tokens = conn.zrange('recent:', 0, end_index - 1)
session_keys = []
for token in tokens:
session_keys.append('viewed:' + token)
conn.delete(*session_keys)
conn.hdel('login:', *tokens)
conn.zrem('recent:', *tokens)购物车功能
在过去,网站常常将购物车功能集成在cookie当中,这样做的缺点就是会导致cookie体积过大,拖慢请求速度;此外,网站对cookie的验证也会变得困难。
在上一节我们做到了将会话cookie以及用户最近浏览商品存储在redis中,接下来我们可以尝试将购物车也存储在redis中。
购物车的结构非常简单,使用散列存储商品id与数量的映射,利用cart与用户token形成命名空间。不过添加购物车之后在上面清理token的部分就需要添加对购物车的清理。
def add_to_cart(conn, session, item, count):
if count <= 0:
conn.hrem('cart:' + session, item)
else:
conn.hset('cart:' + session, item, count)通过这一系列的优化,我们就可以通过较低的代价获取到用户最近浏览的商品,用户加入购物车的商品,用户下单的商品这些数据源,方便后续分析。
网页缓存
接下来就是最常用的缓存网页响应操作。对于大多数动态生成,但数据变化次数极少的网页,我们可以使用redis将请求的响应缓存下来,在下一次接收到请求之后直接调取缓存中的响应,减少响应时间也减轻了服务器的负担。
tip:中间件:能够在处理请求之前或之后添加层的框架
def cache_request(conn, request, callback):
if not can_cache(conn, request):
return callback(request)
page_key = 'cache:' + hash_request(request)
content = conn.get(page_key)
if not content:
content = callback(request)
conn.setex(page_key, content, 300)
return content数据行缓存
考虑到有一部分页面只需要表中的一部分数据行,这些页面势必无法整个缓存下来,但如果每次请求页面都去查询的话又会给数据库带来极大的压力。因此这里我们就要考虑缓存部分需要的数据行来提升效率。
如果上面的描述过于抽象的话就想一想淘宝的特价促销页面吧。
这方面优化的具体做法是:编写一个守护进程函数,让他定期将数据行更新到缓存中。这里数据行在redis中的数据结构为字符串,键为类型+商品id,值为JSON格式的商品属性。调度的处理方法为使用两个有序集合,一个负责记录何时进行调度,成员为数据行id,值为更新该数据的时间戳。另一个负责记录延时,成员为数据行id,值为更新数据的间隔。
def schedule_row_cache(conn, row_id, delay):
conn.zadd('delay:', row_id, delay) # 添加延迟
conn.zadd('schedule:', row_id, time.time()) # 立即进行调度def cache_rows(conn):
while not QUIT:
# 获取下一个调度的商品
next = conn.zrange('schedule:', 0, 0, withscores=True)
now = time.time()
# 如果没有商品或还没轮到则休眠后继续
if not next or next[0][1] > row:
time.sleep(.05)
continue
row_id = next[0][0]
delay = conn.zscore('delay:', row_id)
if delay <= 0:
conn.zrem('delay:', row_id)
conn.zrem('schedule:', row_id)
conn.delete('inv:' + row_id)
continue
row = Inventory.get(row_id)
conn.zadd('schedule:', row_id, now + delay)
conn.set('inv:' + row_id, json.dump(row.to_dict))tip:redis不支持数据结构的嵌套,因为这会导致命令语法复杂性直线上升。如果希望达成类似的效果可以在命名空间尝试分割例如user:123存储用户信息,user:123:posts存储用户发表的文章。
网页分析
上面我们通过缓存web页面来减少页面载入时间,但假如我们在内存大小有限的情况下,缓存所有的页面就不太现实了。这时候就需要有选择性的去缓存,比如缓存访问量前10000的商品。
这就需要我们再添加一个有序列表来记录各个商品的访问量,每当商品被访问后,它对应的分数就-1,这样访问量最多的商品就会排在列表的第一位。
def update_token(conn, token, user, item=None):
timestamp = time.time()
conn.hset('login:', token, user) # 维护用户和令牌的映射关系
conn.zadd('recent:', token, timestamp) # 记录token最后一次使用时间
if item:
conn.zadd('viewed:' + token, item, timestamp) # 添加最近浏览的商品
conn.zremrangebyrank('viewed:' + token, 0, -26) # 移除旧的记录,只保留最近的25个
conn.zincrby('viewed:', item, -1) # 增加访问量 同时为了减少内存的使用,我们只记录指定数量的商品。这需要一个守护进程函数去定期进行修剪。
def rescale_viewed(conn):
while not QUIT:
conn.zremrangebyrank('viewed:', 0, -20001) # 删除排名在2000后的商品
conn.zinterstore('viewed:', {'viewed:':.5})
time.sleep(300)接下来就是修改can_cache,用新的逻辑来判断是否需要缓存
def can_cache(conn, request):
item_id = extract_item_id(request)
if not item_id or is_dynamic(request):
return False
rank = conn.zrank('viewed:', item_id)
return rank is not None and rank < 10000Redis命令
字符串
redis字符串可以存储以下三种数据
- 字节串
- 整数(长整型)
- 浮点数(double)
当用户向redis中存储字符串时,如果它可以被解释成整数或是浮点数,redis会察觉到这一点并提供增减值的方法,如果对字节串进行增减操作则会收到一个错误反馈。如果对不存在与redis中的键执行增减方法,redis会先将键对应的值初始化为0,然后再执行指定的操作。
Redis中的自增和自减命令
| 命令 | 用例和描述 |
|---|---|
| INCR | INCR key-name 将键存储的值加1 |
| DECR | DECR key-name 将键存储的值减1 |
| INCRBY | INCRBY key-name amount 将键存储的值加amout |
| DECRBY | DECRBY key-name amount 将键存储的值减amout |
| INCRBYFLOAT | INCRBYFLOAT key-name amount 将键存储的值加浮点数amout |
Redis处理子串和二进制位的命令
| 命令 | 用例和描述 |
|---|---|
| APPEND | APPEND key-name value 将value追加到给定key当前存储的串的末尾 |
| GETRANGE | GETRANGE key-name start end 获取由偏移量start到end范围内所有字符组成的子串 |
| SETRANGE | SETRANGE key-name offset value 将从偏移量offset开始的字符串设置为给定值 |
| GETBIT | GETBIT key-name offset 将字节串看作是二进制位,并返回串中偏移量为offset的二进制位的值 |
| SETBIT | SETBIT key-name offset value 将字节串二进制位中偏移量为offset的位设为value |
其中处理子串的方法,对于超出原有长度的部分都会当作空串处理,例如setrange在处理超出原本字符串长度的偏移量时,其作用就相当于将新的值添加在字符串末尾。
列表
列表是一个由多个字符串组成的有序序列结构,可以用于存储任务信息,最近浏览过的文章或常用联系人信息。
| 命令 | 用例和描述 |
|---|---|
| RPUSH | RPUSH key-name value [value …] 将若干个值推入列表的右侧 |
| LPUSH | LPUSH key-name value [value …] 将若干个值推入列表的左侧 |
| RPOP | RPOP key-name 移除并返回列表右侧的元素 |
| LPOP | LPOP key-name 移除并返回列表左侧的元素 |
| LINDEX | LINDEX key-name offset 返回本列表中偏移量为offset的元素 |
| LRANGE | LRANGE key-name start end 返回列表中第start到第end个元素 |
| LTRIM | LTRIM key-name start end 对列表进行修剪,只保留从start到end的元素 |
其中LTRIM和LRANGE的组合使用可以做到功能上类似LPOP和RPOP,但能够一次返回多个元素。
127.0.0.1:6379> rpush list a b c d
(integer) 4
127.0.0.1:6379> ltrim list 1 2
OK
127.0.0.1:6379> lrange list 0 -1
1) "b"
2) "c"以上的所有方法在列表中没有可以使用的元素时都会返回nil,但redis还提供了使用阻塞队列的列表方法,在列表中没有可用元素时不会立即返回而是阻塞一段时间等待可用元素。
阻塞式的列表弹出命令以及在列表间移动元素的命令
| 命令 | 描述 |
|---|---|
| BLPOP | BLPOP key-name [key-name …] timeout 从遇到的首个非空队列中弹出最左边的元素,或者阻塞timeout秒并等待可以弹出的元素。 |
| BRPOP | BRPOP key-name [key-name …] timeout 从遇到的首个非空队列中弹出最右边的元素,或者阻塞timeout秒并等待可以弹出的元素。 |
| RPOPLPUSH | RPOPLPUSH source-key dest-key 从source-key最右边弹出一个元素,假如dest-key的最左端,并将这个元素返回给用户 |
| BRPOPLPUSH | BRPOPLPUSH source-key dest-key timeout 和上面一个命令效果一样,区别在于如果source-key中没有元素,就阻塞timeout秒并等待可弹出的元素 |
集合
Redis的集合以无序的方式来存储多个各不相同的元素,可以快速执行添加元素操作,移除元素操作以及检查一个元素是否存在于集合里。
| 命令 | 描述 |
|---|---|
| SADD | SADD key-name item [item …] 将一个或多个元素添加到集合里,并返回被添加进去的元素数量 |
| SREM | SREM key-name item [item …] 从集合中移除一个或多个元素,并返回被移除的元素的数量 |
| SISMEMBER | SISMEMBER key-name item 检查元素item是否存在于集合key-name里 |
| SCARD | SCARD key-name 返回集合包含的元素数量 |
| SMEMBERS | SMEMBERS key-name 返回集合包含的元素数量 |
| SRANDMEMBER | SRANDMEMBER key-name [count] 从集合里随机返回一个或多个元素。当count为正数时,返回的随机元素不会重复。当count为负数时,返回的元素可能会重复。 |
| SPOP | 随机移除集合中的一个元素,并返回被移除的元素 |
| SMOV | SMOV source-key dest-key item 如果集合source-key包含元素item,那从中移除item并添加到dest-key中。如果item被成功移除就返回1否则返回0。 |
以上就是redis集合的基本操作,接下来介绍集合间的组合与关联,这也是集合最有用的方法。
| 命令 | 描述 |
|---|---|
| SDIFF | SDIFF key-name [key-name …] 返回存在于第一个集合但不存在与其他集合中的元素 |
| SDIFFSTORE | SDIFFSTORE dest-key key-name [key-name …] 将差集运算的结果存储到dest-key里 |
| SINTER | SINTER key-name [key-name …] 返回交集运算的结果 |
| SINTERSTORE | SINTERSTORE dest-key key-name [key-name …] 将交集运算的结果存储到dest-key中 |
| SUNION | SUNION key-name [key-name …] 返回并集运算的结果 |
| SUNIONSTORE | SUNIONSTORE dest-key key-name [key-name …] 将并集运算的结果存储到dest-key中 |
散列
Redis的散列可以将多个键值对存储在一个Redis键里面。因此散列非常适合将一些相关的数据存储在一起。
| 命令 | 描述 |
|---|---|
| HMGET | HMGET key-name key [key …] 从散列里面获取一个或多个键的值 |
| HMSET | HMSET key-name key value [key value …] 为散列里面的一个或多个键设置值 |
| HDEL | HDEL key-name key [key …] 删除散列里面的一个或多个键值对,返回成功找到并删除的键值对数量 |
| HLEN | HLEN key-name 返回散列包含的键值对数量 |
像是这一类批量处理的命令,既可以给用户带来便利,同时也可以通过减少命令的调用次数以及客户端与redis之间通信往返的次数来提升redis性能。
| 命令 | 描述 |
|---|---|
| HEXISTS | HEXISTS key-name key 检查给定键是否存在于散列中 |
| HKEYS | HKEYS key-name 获取散列包含的所有键 |
| HVALS | HVALS key-name 获取散列包含的所有值 |
| HGETALL | HGETALL key-name 获取散列包含的所有键值对 |
| HINCRBY | HINCRBY key-name key increment 将键key存储的值加上increment |
| HINCRBYFLOAT | HINCRBYFLOAT key-name key increment 将键key存储的值加上浮点数increment |
虽然HGETALL可以获取所有的键值对,但并不代表HKEYS和HVALS就没有用处。如果散列的值非常大,那么可以先使用HKEYS获取散列包含的所有键,然后再一个一个取出值,避免因一次获取多个大体积的值而导致服务器阻塞。
有序集合
有序集合存储成员与分值之间的键值对映射,并且提供分值处理,以及根据分值大小有序的获取或扫描成员和分值。
| 命令 | 描述 |
|---|---|
| ZADD | ZADD key-name score member [score member …] 添加若干个成员,分数键值对到集合中去。 |
| ZREM | ZREM key-name member [member …] 移除给定的成员,并返回移除的数量。 |
| ZCARD | ZCARD key-name 返回有序集合包含的成员数量 |
| ZINCRBY | ZINCRYBY key-name increment member 将指定成员的分数加上increment |
| ZCOUNT | ZCOUNT key-name min max 返回分数介于min和max之间的成员数量 |
| ZRANK | ZRANK key-name member 返回指定成员的排名 |
| ZSCORE | ZSCORE key-name member 返回指定成员的分数 |
| ZRANGE | ZRANGE key-name start stop [WITHSCORES] 返回有序集合中排名介于start和stop之间的成员。如果给定了WITHSCORES,则会连分值一并返回 |
| 命令 | 描述 |
|---|---|
| ZREVRANK | ZREVRANK key-name member 返回有序集合里成员member的排名。这里按分值从大到小排 |
| ZREVRANGE | ZREVRANGE key-name start stop [WITHSCORES] 返回有序集合给定排名范围内的成员,同样是从大到小排 |
| ZRANGEBYSCORE | ZRANGEBYSCORE min max [WITHSCORES] [LIMIT offset count] 返回有序集合中,分值介于min和max的成员 |
| ZREVRANGEBYSCORE | 功能同上,但顺序相反 |
| ZREMRANGEBYRANK | ZREMRANGEBYRANK key-name start stop 移除有序集合中排名介于start和stop之间的成员 |
| ZREMRANGEBYSCORE | ZREMRANGEBYSCORE key-name min max 移除有序集合中分值介于min和max之间的所有成员 |
| ZINTERSTORE | ZINTERSTORE dest-key key-count key [key …] [WEIGHTS weight …] [AGGREGATE SUM|MIN|MAX] 对给定有序集合执行交集运算 |
| ZUNION | ZUNION dest-key key-count key [key …] [WEIGHTS weight …] [AGGREGATE SUM|MIN|MAX] 对给定有序集合执行并集运算 |
这里稍微解释一下redis中的集合运算,当若干个有序集合进行集合运算后,其成员部分的结果和我们熟知的数学意义上的集合运算结果一致。而分数部分则由用户传入的WEIGHT和AGGREGATE决定,WEIGHT可以决定各个集合中分数的权重,默认为1。AGGREGATE则决定集合之间找到匹配项后对分数的处理行为,是直接相加还是取最大或最小值。
发布与订阅
订阅者可以订阅指定的频道,发布者可以向指定的频道传输信息,这些信息一旦被传输到给定频道,所有订阅该频道的订阅者都会收到信息。
Redis也提供了一系列用于发布与订阅的命令
| 命令 | 描述 |
|---|---|
| SUBSCRIBE | SUBSCRIBE channel [channel …] 订阅给定的一个或多个频道 |
| UNSUBSCRIBE | UNSUBSCRIBE channel [channel …] 退订给定的一个或多个频道,如果没有指定,就退订所有频道 |
| PUBLISH | PUBLISH channel msg 向给定频道发送信息 |
| PSUBSCRIBE | PSUBSCRIBE pattern [pattern …] 订阅与给定模式相匹配的所有频道 |
| PUNSUBSCRIBE | PUNSUBSCRIBE pattern [pattern …] 退订与给定模式相匹配的所有频道 |
| 虽然redis的订阅发布模式很有用,但其也有一定的局限性: |
- 如果一个客户端订阅了某个频道,但其自身的读取速度不够快,这时就会导致大量的消息积压在redis的输出缓冲区,这可能会降低redis的效率,甚至对OS造成伤害。不过在新版的redis中,它会自动断开不符合输出缓冲区大小限制的订阅客户端。
- 任何网络系统在执行操作时都可能会碰上断线,如果客户端在执行订阅发布的过程中断线,那就会丢失掉断线期间的所有数据。
排序命令
redis中的sort命令可以同时处理字符串,集合,列表和散列。sort命令可以根据字符串,列表,集合,有序集合,散列这5种键里面存储的数据,对列表,集合,以及有序集合进行排序。
| 命令 | 描述 |
|---|---|
| SORT | SORT source-key [BY pattern] [LIMIT offset count] [GET pattern [GET pattern …]] [ASC|DESC] [ALPHA] [STORE dest-key]——根据给定的选项,对输入列表、集合或者有序集合进行排序,然后返回或者存储排序的结果 |
| 这里就大致讲一下BY和GET参数的意义 | |
| 有时我们希望能够自定义排序规则,例如列表中的数字都有不同的权重,而这些权重值存储在weight_*当中,其中的*代表列表中的数字元素,sort命令会根据列表中的元素去散列weight_之中寻找匹配的权重,并进行排序。 | |
| 每次排序完成后都会返回顺序列表,但有时我们希望获取的是外部数据,例如对应的权重,这时就可以使用到GET,匹配方式和BY相同。 |
127.0.0.1:6379> rpush sort-input 23 15 110 7
(integer) 4
127.0.0.1:6379> hset d-7 field 5
(integer) 1
127.0.0.1:6379> hset d-23 field 30
(integer) 1
127.0.0.1:6379> hset d-110 field 1
(integer) 1
127.0.0.1:6379> hset d-15 field 5
(integer) 1
# 根据d-*中field的值对sort-input进行排序
127.0.0.1:6379> sort sort-input by d-*->field
# 排序后返回权重值
127.0.0.1:6379> sort sort-input by d-*->field get d-*->field基本事务
redis的基本事务要使用到MULTI和EXEC命令,MULTI命令代表事务的开始,EXEC代表事务的结束。一旦事务开启,Redis就只会处理该客户端的命令,被上述两条命令包裹的命令会一个接一个执行直到所有命令都完成。
在Redis接到MULTI命令之后,就会将该客户端后续发送的所有命令都放入一个队列里面,并在不被打断的情况下完成里面的所有命令。这种做法不仅可以有效解决并行状态下的问题,还可以减少与redis的通信往返次数,以此提升效率。
这里要特别注意的是,和数据库事务不同,在redis中事务的所有操作都不会被立刻执行,而是缓存在一个队列里,只有在执行过程中,他才是无法打断的。这种事务更接近于一种消息队列。
127.0.0.1:6379> multi
OK
127.0.0.1:6379(TX)> hset test o gg
QUEUED
127.0.0.1:6379(TX)> hset test niubi 1
QUEUED
127.0.0.1:6379(TX)> hget test niubi
QUEUED
127.0.0.1:6379(TX)> exec
1) (integer) 0
2) (integer) 1
3) "1"在第二章中提到,用户操作与token删除之间有一个竞争关系,我们可以让二者以事务的方式执行,这样就可以有效避免竞争。
键的过期时间
对于那些在某个时间点之后就不再有用的数据,我们可以通过设置过期时间来让一个键在给定时间之后自动删除。
不过这种做法也有限制,对于那些无法原子地为键设置过期时间的情况,这种方法就有点鸡肋了。因此,设置过期时间往往只适用于字符串类型,或是在指定时间后可以直接完全删除,而非删除数据结构中指定部分的情况。
| 命令 | 描述 |
|---|---|
| PERSIST | PERSIST key-name 移除键的过期时间 |
| TTL | TTL key-name 查看给定键距离过期还有多少时间 |
| EXPIRE | EXPIRE key-name seconds 让给定键在指定的秒数过后过期 |
| EXPIREAT | EXPIREAT key-name timestamp 将给定键的过期时间设置为给定的UNIX时间戳 |
| PTTL | PTTL key-name 查看给定键距离过期还有多少毫秒 |
| PEXPIRE | PEXPIRE key-name milliseconds 让给定键在指定的毫秒之后过期 |
| PEXPIREAT | PEXPIREAT key-name timestamp-milliseconds 让一个毫秒级精度的UNIX时间戳设置为给定键的过期时间 |
Redis线程模型
我们常说Redis是单线程的,这里指的是Redis在处理命令时只使用主线程,但这并不代表Redis只有一个线程,他在启动的时候会启动后台线程,这些后台线程分别负责:
AOF刷盘
关闭文件
释放内存
之所以将这些任务交给后台线程,是因为这些都是十分耗时的任务,放在主线程中会大幅降低效率。

上图是Redis线程模型的具体执行流程:
Redis首先会检查写发送队列里是否有待发送的数据,如果有就调用write函数发送数据,如果没有发送完,就注册写事件来处理函数。
接着就会调用epoll_wait等待事件到来:
如果连接事件到来,调用accept获取已连接socket,然后把它注册到epoll中,最后注册读事件
如果是读事件,使用read接收数据,接着解析指令,执行指令。然后把客户端发送对象添加到发送队列,把执行结果写入缓冲区等待发送
如果是写事件,调用write发送数据,如果没有发完,就注册写事件,等待有数据可发后再发。
数据安全与性能保障
持久化选项
快照:将存在与某一时刻的所有数据都写入硬盘
只追加文件(AOF):在执行写命令时,将该命令复制到磁盘里。
一般来说,将数据持久化到磁盘的目的主要是为了之后重用数据,或为了防止系统故障而将数据备份到一个远程位置。此外,redis中也可能存储着复杂任务的执行结果,若能存储起来就可以避免后续的计算。
快照持久化选项
save 60 1000 60秒内若有1000次更改就执行存储以此快照
stop-writes-on-bgsave-error no
rdbcompression yes
dbfilename dump.rdb 快照文件
AOF 持久化选项
appendonly no
appendfsync everysec
no-appendfsync-on-rewrite no
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
dir ./ 决定快照文件和AOF文件的保存路径快照
创建快照
- 客户端可以向服务器发送一个
bgsave命令来创建快照。服务器接收到之后会fork一个子进程将快照内容写入磁盘,父进程继续处理请求。 - 客户端还可以发送
save命令来创建快照。接到save命令的服务器会停止处理一切客户端请求,开始创建快照。一般只用在内存不足的情况。 - 当满足了上面设置的save要求后,也会自动触发
bgsave创建快照。 - 当redis接收到
shutdown命令或接收到标准trem信号时,会执行save命令,并在完成后关闭服务器。 - 当一个Redis服务器连接另一个Redis服务器,并向对方发送
SYNC命令来开始一次复制操作的时候,如果主服务器目前没有在执行BGSAVE操作,或者主服务器并非刚刚执行完BGSAVE操作,那么主服务器就会执行BGSAVE命令。
在使用快照之前,首先必须意识到,如果系统真的崩溃,用户将丢失最近一次生成快照之后更改的所有数据。因此快照只适合于即使丢失一部分数据也不会造成问题的应用。
执行流程
当Redis服务器执行RDB快照时,会fork出一个子进程执行相关操作,具体流程同AOF。不过需要注意的时,RDB期间服务器通过写时复制修改的内容不会在本次RDB中被写入RDB文件,只能等待下一次bgsave或save执行。
使用场景
个人开发
在个人开发服务器上,我们主要考虑的是尽可能降低快照持久化带来的资源消耗。如果打算在服务器中使用快照持久化,并存储大量的数据,那尽量让开发服务器的硬件配置接近生产服务器的配置,方便快速判断快照生成频率是否恰当。
对日志进行聚合运算
在对日志文件进行聚合计算或者对页面浏览量进行分析时,唯一要考虑的是,如果redis因崩溃而没能创建快照,我们可以承受丢失多长时间内产生的数据,并在配置文件中用save做好处理。除此之外,还要解决如何恢复因故障而被终端的日志操作。
在数据恢复时,首先要做的是弄清楚丢失了哪些数据。因此在处理日志的同时要记录被处理日志的有关信息。
def process_logs(conn, path, callback):
# 获取文件当前的处理进度
current_file, offset = conn.mget('progress:file', 'progress:position')
pipe = conn.pipeline()
def update_progress():
pipe.mset({
'progress:file':fname,
'progress:position':offset
})
# 执行日志更新操作,并记录日志名以及偏移量(处理进度)
pipe.execute()
for fname in sorted(os.listdir(path)):
# 跳过已经完成处理的文件
if fname < current_file:
continue
inp = open(os.path.join(path, fname), 'rb')
# 跳过目标日志已被处理的部分
if fname == current_file:
inp.seek(int(offset, 10))
else:
offset = 0
current_file = None
for lno, line in enumerate(inp):
callback(pipe, line) # 调用回调函数处理日志行
offset += int(offset) + len(line) # 更新偏移量
# 每处理1000个日志行或处理完一个日志文件就更新以此日志处理进度
if not (lno + 1) % 1000:
update_progress()
update_progress()
inp.close() 大数据
可以通过调用使用save,而非bgsave减少redis在备份时的停顿时间。可以取消配置文件中自动的save,转而用手动的方式(发送save命令)来处理快照的生成
AOF
AOF持久命令会将被执行的写命令写到AOF文件的末尾,以此来记录数据的变化。因此只需要从头到尾执行一遍AOF文件包含的写命令就可以恢复AOF文件记录的数据集。
文件同步
向硬盘写入文件时,要经历以下阶段:
当调用写入方法时,内容会先被存储到缓冲区,然后操作系统会在将来的某个时候将缓冲区存储的内容写入硬盘。
| 选项 | 同步频率 |
|---|---|
| always | 每个Redis写命令都要同步写入硬盘,这样做会严重降低Redis的速度 |
| everysec | 每秒执行一次同步,显式将多个写命令同步到磁盘 |
| no | 让操作系统来决定何时同步 |
一般来说使用everysec选项就足够了,no选项虽然可以让redis的性能免受AOF影响,但却会导致崩溃后不定量的数据缺失。
如果不想让自己的固态尽早报废,不要使用always选项。重写/压缩AOF文件
AOF虽然可以很大程度上减少数据丢失的量,并且能在极短时间内完成持久化操作。但其并非十全十美。
随着时间推移,AOF的文件体积会不断增长,占用大量的磁盘空间,同时redis每次重启都要执行AOF中的写明了来还原数据集,如果AOF非常大,还原会非常缓慢。
为解决AOF体积不断增大的问题,用户可以向redis发送BGREWRITEAOF命令,它会通过移除AOF文件中的冗余命令来重写AOF文件。要注意的是,该命令的执行逻辑与快照BGSAVE基本相同,因此有同样的缺陷。在使用时要谨慎选择时间段,因为如果AOF非常大的话,内存和时间消耗会很大。auto-aof-rewrite-percentage:当AOF体积达到最小体积阈值的指定百分比时开始重写auto-aof-rewrite-min-size:AOF在磁盘上可接受的最小文件大小
AOF重写流程
当AOF重写开始后,会fork出一个子进程来执行相关操作。使用进程而非线程的原因是,子线程与父进程共享内存,在执行修改时必须通过加锁来保证数据一致性。而使用进程,我们就可以通过COW避免加锁带来的开销。
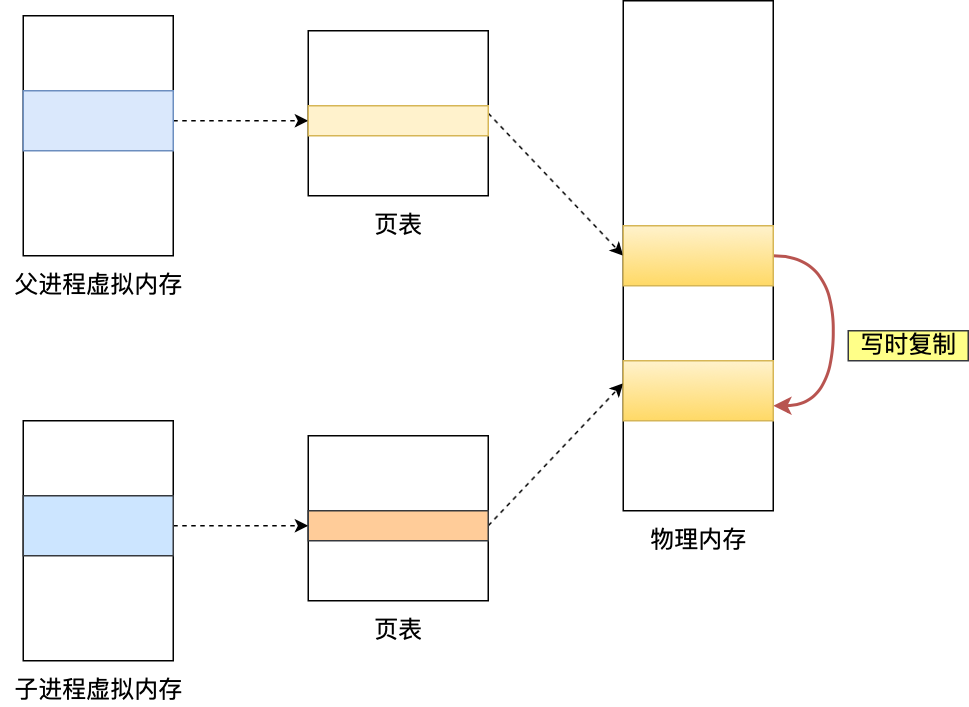
COW在AOF中的应用
主线程通过fork调用生成子进程时,操作系统会将主进程的页表复制一份给子进程,这个页表记录虚拟地址和物理地址映射关系,而不会复制物理内存。
这样一来,子进程就和父进程共享了物理内存数据,同时页表对应的页表项也会标记为只读。
当子进程或父进程想要修改共享内存中的数据时,就会触发写时复制,此时OS就会进行物理内存的复制,并重新设置内存映射关系。这个新的页表专属于发起修改的一方,它具有读写权限
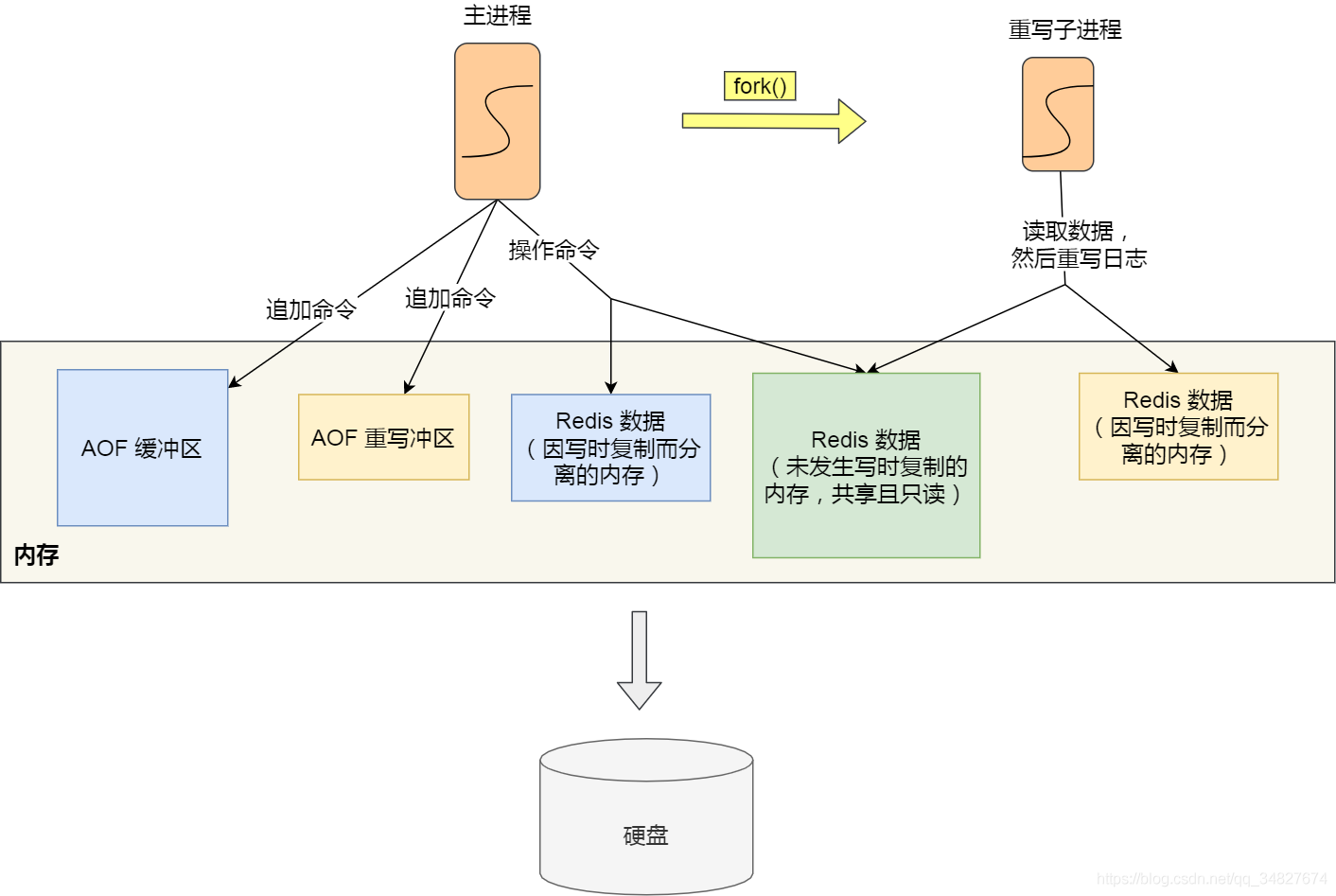
既然使用了写时复制,那么父进程在AOF期间进行的修改操作对执行AOF的子进程就是不可见的了,这显然会导致数据不一致。因此,父进程会将新写入的数据写入AOF缓冲区(等待被写入AOF文件的缓冲区)和AOF重写缓存区(处理AOF重写的缓冲区)。当子进程完成AOF时会向父进程发送一个信号,此时父进程会将AOF重写缓冲区的所有内容追加到AOF文件中,并重命名。
混合持久化
通过上面的讨论,我们可以看出AOF和RDB都各有优劣。而为了最大程度上利用二者的优势,Redis推出了混合持久化。
开启混合持久化后,进行AOF重写时,fork出来的重写子进程会先将与主线程共享的内存数据以RDB的形式写入AOF文件。在此期间主线程处理的写操作会写入到AOF重写缓冲区,最后它会以增量命令的形式被写入AOF文件。写入完成后通知主线程将新的含有RDB格式和AOF格式的文件替换掉旧的AOF文件。
这样做的好处在于,重启Redis加载数据时,由于数据量很大的部分使用RDB存储,它的加载速度会很快。而之后一些琐碎的修改使用AOF存储,可以很大程度上减少数据的丢失。
复制
让其他服务器拥有一个不断更新的数据副本,使得拥有数据副本的服务器可以用于处理用户发送的请求。
在需要扩展读请求或是在需要写入临时数据的时候,用户可以通过设置额外的Redis从服务器来保存数据集的副本。客户端每次向主服务器进行写入时,从服务器都会实时地得到更新。
准备工作
前文提到当主服务器被连接时,会存储一份快照,因此要确保主服务器的dir,dbfilename被正确配置,并且拥有相应的权限。
从服务器可以同过slaveof host port来连接主服务器,也可以通过slaveof no one让服务器停止复制操作。
启动过程
| 步骤 | 主服务器操作 | 从服务器操作 |
|---|---|---|
| 1 | 等待命令进入 | 连接主服务器,发送SYNC命令 |
| 2 | 开始执行BGSAVE,并使用缓冲区记录BGSAVE之后执行的所有写命令 | 根据配置选项来决定是继续使用现有的数据响应请求还是向发送请求的客户端返回错误 |
| 3 | BGSAVE执行完毕,向从服务器发送快照文件,并在发送期间继续使用缓冲区记录被执行的写命令 | 丢弃所有旧数据,开始载入发来的快照文件 |
| 4 | 快照文件发送完毕,开始向从服务器发送存储在缓冲区里面的写命令 | 完成对快照文件的解释操作,像往常一样开始接收命令请求 |
| 5 | 缓冲区存储的写命令发送完毕;从此开始,每执行一个写命令,就向从服务器发送相同命令 | 执行主服务器发来的所有写命令 |
从上面的步骤不难看出,Redis的主从交互需要网络畅通,同时最好在主服务器中预留下30%-45%的内存用于执行BGSAVE和创建记录写命令的缓冲区。
当有多台从服务器尝试连接主服务器时,就会出现下面两种情况之一:
- 快照还没发送:所有从服务器收到相同的快照和写命令
- 快照正在发送或已经发送:当主服务器与较早进行连接的从服务器执行完复制所需的5个步骤之后,主服务器会与新连接的从服务器执行一次新的步骤1至步骤5
考虑到主从服务器间的网络不可能永远畅通,我们必须准备一些应对网络问题的措施。当发生主从服务器断开连接后又重新连接的情况时,最简单的处理方式就是让它们再进行一次全量复制,这显然是非常耗时的。
因此,面对这种情况,Redis采用了增量复制,当从服务器重新连接主服务器后,它仍会向主服务器发送psync,不过这次offset值不再是-1(全量复制时为-1)。主服务器收到后会发送CONTINUE命令,告诉从服务器这是一次增量复制。
主服务器处理增量复制的方式
主服务器会维护一个环形缓冲区,里面记录了所有最近执行的命令,同时主服务器也会维护一个变量用于记录自己写到哪里了。
主服务器在收到从服务器的psync命令后,会比较收到的offset和自己维护的写入offset,如果从服务器缺失的数据还在环形缓冲区里,就会执行增量复制,否则会执行全量复制。
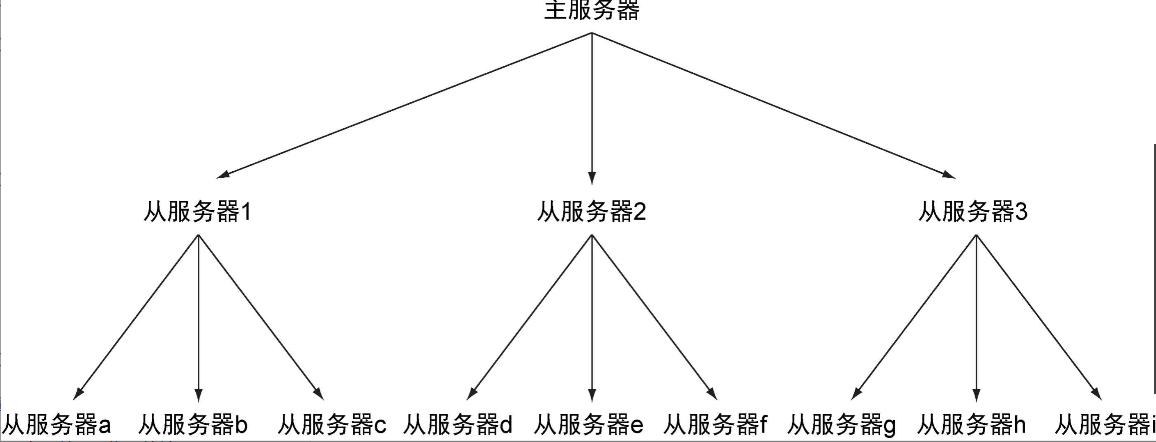
主从链
创建太多个从服务器可能会造成网络不可用,尤其是在复制需要通过互联网或在不同数据中心之间进行时。为了缓解这一问题,我们让从服务器也可以拥有自己的从服务器,并由此形成主从链。
从从复制和主从复制的区别在于,如果从服务器X拥有从服务器Y,那么当从服务器执行复制步骤4时,会断开与服务器Y的连接,导致从服务器Y需要重新连接并重新同步。
当读请求的重要性明显高于写请求的重要性,并且读请求的数量远远超出一台Redis服务器可以处理的范围时,用户就需要添加新的从服务器来处理读请求。随着负载不断上升,主服务器可能会无法快速地更新所有从服务器,或者因为重新连接和重新同步从服务器而导致系统超载。为了缓解这个问题,用户可以创建一个由Redis主从节点(master/slave node)组成的中间层来分担主服务器的复制工作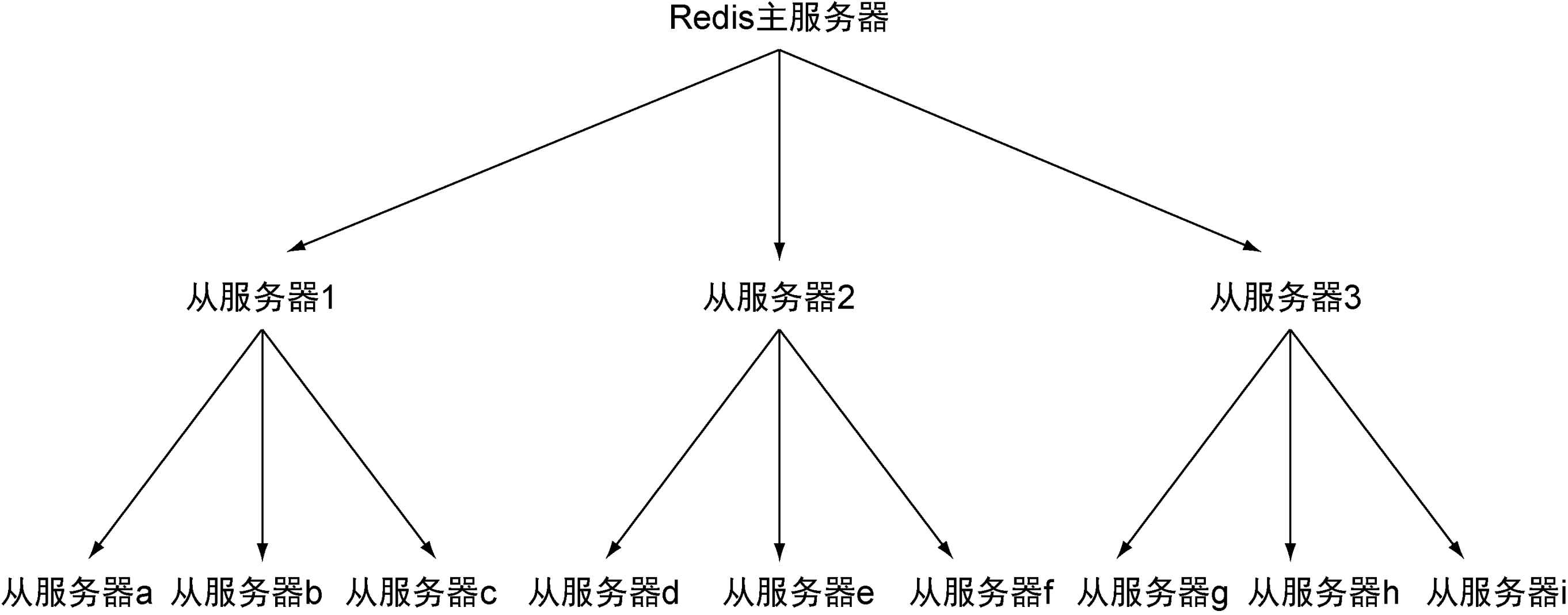
检验硬盘写入
验证主服务器发送的数据是否被从服务器写入磁盘需要以下两个步骤:
- 判断数据是否已经到达了从服务器:向主服务器写入真正的数据后,再向主服务器写入一个唯一的虚构值,然后通过检查虚构值是否存在于从服务器来判断写数据是否到达从服务器。
- 判断从服务器是否已经把数据写入了磁盘:检查
INFO命令的输出结果中aof_pending_bio_fsync的属性值是否为0。
def wait_for_sync(mconn, sconn):
identifier = str(uuid.uuid4()) # 用于判断数据是否抵达的虚拟值
mconn.zadd('sync:wait', identifier, time.time())
# 等待服务器完成同步
while not sconn.info()['master_link_status'] != 'up':
time.sleep(.001)
# 等待从服务器接收数据
while not sconn.zscore('sync:wait', identifier):
time.sleep(.001)
# 检查数据是否已经被写入磁盘,1s后超时
deadline = time.time() + 1.01
while time.time() < deadline:
if sconn.info()['aof_pending_bio_fsync'] == 0:
break
time.sleep(.001)
# 清理令牌,同时清理之前可能留下的旧令牌
mconn.zrem('sync:wait', identifier)
mconn.zremrangebyscore('sync:wait', 0, time.time() - 900)减少数据丢失
异步复制
Redis主从复制采用的是异步复制,如果主节点向从节点同步写请求时宕机,主节点内存中的数据就会完全丢失。
Redis配置中有一个参数min-slaves-max-lag。一旦所有的从节点复制/同步数据的耗时都超过了这个配置的值,主服务器就会停止服务,因为它判断,这种情况下继续服务,一旦宕机,会造成大量的数据丢失。
此时客户端可以选择服务降级,先使用本地缓存继续服务,等待主服务器恢复正常后,再重新发起请求。
脑裂
如果主节点无法与从节点交互,也无法响应哨兵的心跳,就会被判断死亡,此时哨兵会选举出一个新的主节点继续服务。
但假如原主节点是由于网络分区的原因而无法进行响应与同步,当主节点连接回来之后,会被哨兵降级为从节点,此时会进行一次全量复制。这导致主节点在被隔离状态下处理的所有写请求都被清理掉,产生数据丢失。
为了处理这种情况,Redis使用两个配置参数:
- min-slaves-to-write x 主节点必须要能与x个节点连接,否则它禁止写入数据
- min-slaves-max-lag x 主从数据复制和同步的延迟不能超过 x 秒
通过上面两个配置,我们能保证主服务器在假死状态下也不会写入数据,当它重新连回集群后,也就不存在数据丢失。
处理系统故障
Redis提供了两个命令用于快照和AOF文件的检查与恢复
redis-check-aof [–fix] <file.aof>
Redis会扫描指定的aof文件,寻找不正确或不完整的命令。如果添加了fix选项,Redis就会删除从第一个不正确命令开始的所有命令。
redis-check-dump <dump.rdb>
Redis检查指定的快照文件是否出错,但无法进行修复。
哨兵
Redis使用哨兵来进行主从故障转移,同时监控主从节点的状态。哨兵节点主要负责三件事:监控,选主,通知
监控
哨兵每隔1秒就会向所有的主从节点发送ping,如果某个节点没有在规定时间内(由配置项down-after-milliseconds设置)响应,就会被判断主观下线。
有主观下线,那么自然也有客观下线,当一个哨兵判断某个节点主观下线后就会向其他哨兵发起命令,询问他们是否也认为这个节点主观下线。如果赞成的哨兵数达到配置项quorum指定的值,该节点就会被判断为客观下线。
选主
当哨兵集群判断主节点客观下线后,就会选派出一个leader节点进行主从故障转移。通常是由判断主节点客观下线的节点担任候选者。
一个候选者要想赢得选举需要以下两个条件:
- 获取半数以上的赞成票
- 获取的票数大于配置项
quorum值
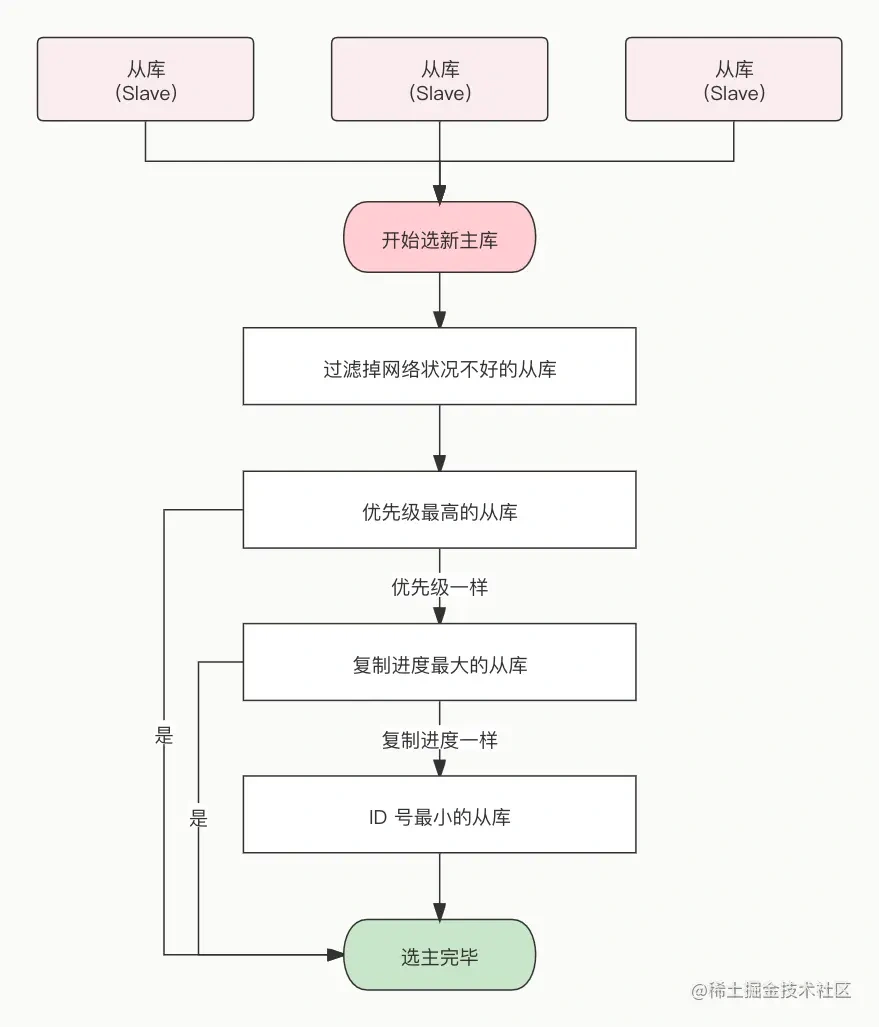
主从故障转移流程:
- 在已下线主节点的所有网络状态良好的从节点中选出一个从节点担任新的主节点。选取标准为:优先级,复制进度,ID号
- 让其余的从节点复制新的主节点
- 将新主节点的IP地址等信息通过发布/订阅模式通知给客户端。
- 继续监视旧主节点,如果它连回集群,将其设为从节点。
哨兵节点之间的发现方式
哨兵之间会通过发布-订阅的方式相互发现,他们通过在订阅主节点上的__sentinel__:hello频道来实现相互发现,首次加入集群的哨兵会往频道中发送自己的IP和端口号,其他哨兵就可以借此获知新成员的信息。
接着,哨兵又可以向主节点发送INFO命令,来获取从节点的信息。
事务
之前已经简单提过了命令的基本操作,但这一部分命令只能够帮助我们以流水线的方式提升程序效率,它并没有对数据一致性的保障。例如,假设一个客户开启了事务,并决定修改某个键,如果此时另一个客户端修改了这个键,事务最终仍会顺利执行,但最终结果却可能天差地别。
在分布式事务的情况下,常常会采用2PC(二阶段提交),但如果连数据一致性都无法维持的话,2PC无法实现。例如,商店进了一批货,老板1更新好了库存,而老板2没更新好库存,这时候这批货就无法被记录,因为老板之间数据不一致,在投票时会发生明显分歧。
为了保证数据的一致性,Redis还提供了WATCH, UNWATCH, DISCARD命令。
WATCH会监视指定的键,在开启WATCH到使用EXEC提交这段时间,如果有其他用户对被监视的键做出了修改,在用户尝试执行EXEC的时候就会返回一个错误。
UNWATCH会取消Redis对所有监视键的监视
DISCARD会取消监视,同时放弃事务中的所有命令
接下来用一个商场案例来解释事务的用法
首先是用户将商品放到商场上销售,这时要监视的键是用户持有物,如果用户将商品挂上去后就用掉了商品,自然是不允许卖出的。
def list_item(conn, itemid, sellerid, price):
inventory = "inventory:%s"%sellerid
item = "%s.%s"%(itemid, sellerid)
end = time.time() + 5
pipe = conn.pipeline()
while time.time() < end:
try:
pipe.watch(inventory)
# 如果指定的商品已经不再用户包裹里,就放弃监视
if not pipe.sismember(inventory, itemid):
pipe.unwatch()
return None
pipe.multi()
pipe.zadd("market:", item, price)
pipe.srem(inventory, itemid)
return True
# 如果出现变动就开始重试
except redis.exceptions.WatchError:
pass
return False而对于购买商品来说,就需要监视商场的货物变化情况以及买家的钱包状况
def purchase_item(conn, buyerid, itemid, sellerid, lprice):
buyer = "users:%s"%buyerid
seller = "users:%s"%sellerid
item = "%s.%s"%(itemid, sellerid)
inventory = "inventory:%s"%buyerid
end = time.time() + 10
pipe = conn.pipeline()
while time.time() < end:
try:
pipe.watch("market:", buyer)
price = pipe.zscore("market:", item)
funds = int(pipe.hget(buyer, "funds"))
if price != lprice or price > funds:
pipe.unwatch()
return None
pipe.multi()
pipe.hincrby(seller, "funds", int(price))
pipe.hincrby(buyer, "funds", int(-price))
pipe.sadd(inventory, itemid)
pipe.zrem("market:", item)
pipe.execute()
return True
except redis.exception.WatchError:
pass
return FalseRedis不像关系型数据库一样,在要访问的数据上加锁,因为持有锁的客户端处理越慢,等待的时间就越长。Redis只会在监视的数据被更改时,通知客户端,避免了等待,当客户端接到失败通知时,只需要尝试重新执行即可。
构建支持程序
日志记录
常用的日志记录方式有两种,第一种是将日志记录到文件里面。然后随着程序的运行不断将新的日志行记录到日志文件中。并在一段时间之后创建新的日志文件。这种日志记录方式很难聚合所有的日志并进行处理。
另一种方式就是本章使用的syslog。该服务运行在Linux服务器的514号TCP端口和UDP端口上,syslog接收其他程序发来的日志并将这些信息路由到存储在硬盘上的各个日志文件中
# 将所有的日志级别映射为字符串
SEVERITY = {
logging.DEBUG: 'debug',
logging.INFO: 'info',
logging.WARNING: 'warning',
logging.ERROR: 'error',
logging.CRITICAL: 'critical'
}
SEVERITY.update((name, name) for name in SEVERITY.values())
def log_recent(conn, name, message, severity=logging.INFO, pipe=None):
severity = str(SEVERITY.get(severity, severity)).lower()
destination = 'recent:%s:%s'%(name, severity)
message = time.asctime() + ' ' + message
pipe = pipe or conn.pipeline() # 使用流水线降低通信次数
pipe.lpush(destination, message) # 将日志加入列表
pipe.ltrim(destination, 0, 99) # 让日志只包含最新的100条
pipe.execute()上面的实例可以很方便的记录最新的日志,但是对于日志的重要程度以及出现频率无法进行统计,因此我们再添加一个用于记录常见日志的方法。
程序会将消息作为成员存储到有序集合里面,并将消息出现的频率设置为成员的分值。为了确保我们看见的常见消息都是最新的,程序会以每小时一次的频率对消息进行轮换,并在轮换日志的时候保留上一个小时记录的常见消息,从而防止没有任何消息存在的情况出现。
程序还需要谨慎处理上一个小时收集到的日志,因为涉及改名操作,因此需要将其放在一个事务里面。此外,程序会将流水线传递给log_recent()来减少记录常见日志和记录最新日志时的通信次数。
def log_common(conn, name, message, severity=logging.INFO, timeout=5):
severity = str(SEVERITY.get(severity, severity)).lower()
destination = 'common:%s:%s'%(name, severity)
start_key = destination + ':start' # 程序每小时轮换一次日志,使用一个键来存储当前所处的时间
pipe = conn.pipeline()
end = time.time() + timeout
while time.time() < end:
try:
# 对记录当前小时数的键进行监视,确保轮换操作正确执行
pipe.watch(start_key)
now = datetime.utcnow().time()
# 获取当前小时数
hour_start = datetime(*now[:4]).isoformat()
existing = pipe.get(start_key)
# 开启事务
pipe.multi()
# 如果记录的是上一个小时的日志,就将他归档
if existing and existing < hour_start:
pipe.rename(destination, destination + ':last')
pipe.rename(start_key, destination + ':pstart')
pipe.set(start_key, hour_start)
elif not existing:
pipe.set(start_key, hour_start)
# 更新日志出现次数
pipe.zincrby(destination, message)
# 记录日志
log_recent(pipe, name, message, severity, pipe)
return
except redis.exception.WatchError:
continue在Redis中存储计数器
在监控应用程序的同时,持续地收集信息是一件非常重要的事情。那些影响网站响应速度以及网站所能服务的页面数量的代码改动、新的广告营销活动或者是刚刚接触系统的新用户,都有可能会彻底地改变网站载入页面的数量,并因此而影响网站的各项性能指标。但如果我们平时不记录任何指标数据的话,我们就不可能知道指标发生了变化,也就不可能知道网站的性能是在提高还是在下降。
在收集指标数据方面,我们可以使用Redis构建一个工具。创建的每一个计数器都有自己的名字,并且会以不同的精度存储最新的数据样本。
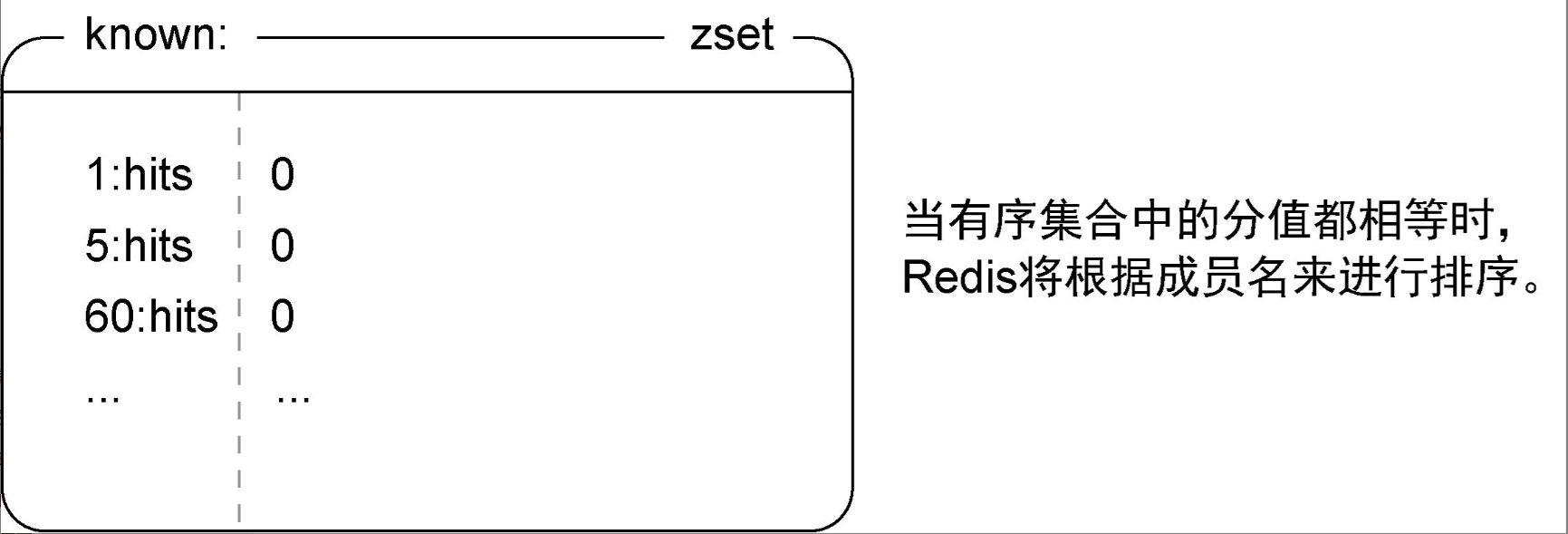
在存储计数器方面,使用hash存储每个计数器在各个时间段的计数,用计数器的名字和频率构成命名空间。除此之外,利用有序集合存储计数器,并将他们的分值全部设为0,这样Redis在排序的时候就会根据成员值排序。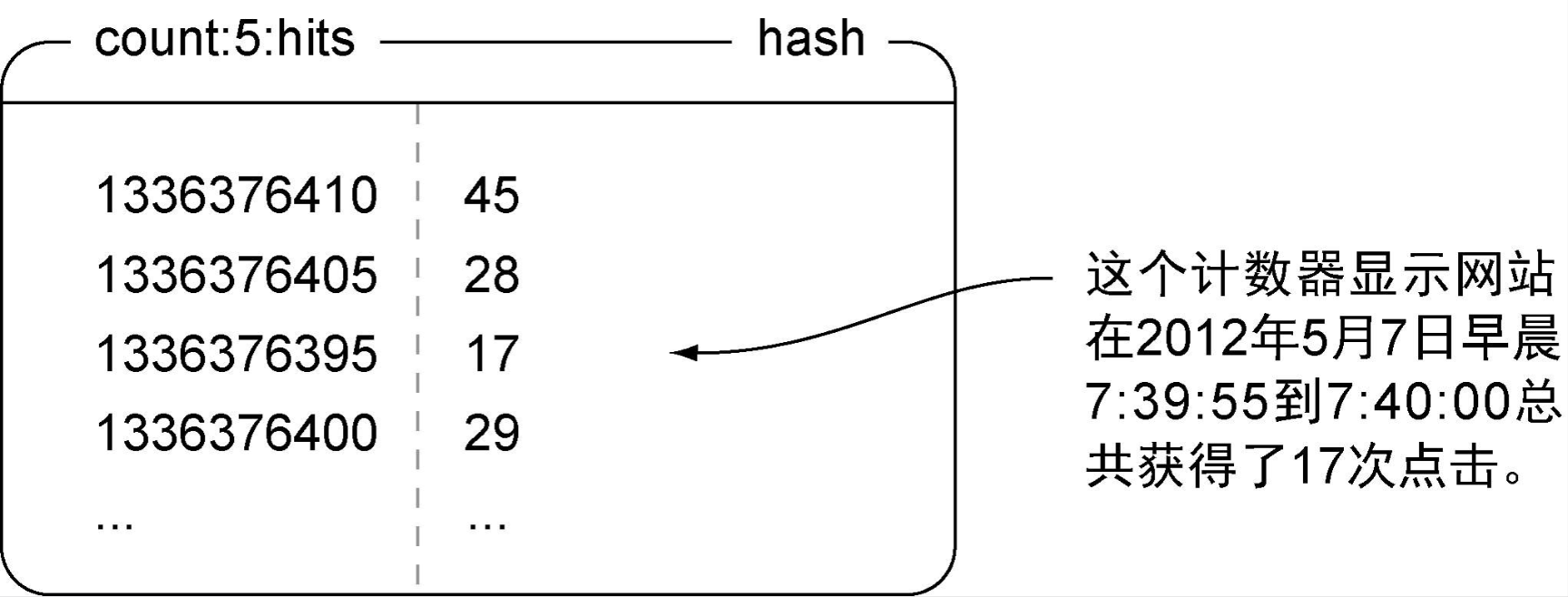
# 计数器精度
PRECISION = [1, 5, 60, 300, 3600]
def update_counter(conn, name, count=1, now=None):
now = now or time.time()
# 用流水线减少消息通信次数
pipe = conn.pipeline()
# 更新各个频率的相关计数器
for prec in PRECISION:
pnow = int(now / prec) * prec
hash = '%s:%s'%(prec, name)
pipe.zadd('known:', hash, 0)
pipe.hincrby('count:' + hash, pnow, count)
pipe.execute()def get_counter(conn, name, precision):
hash = '%s:%s'%(precision, name)
data = conn.hgetall('count:' + hash)
to_return = []
for key, value in data.iteritems():
to_return.append(int(key), int(value))
to_return.sort()
return to_return接下来就是清理计数器了,如果我们只是一味存储数据而不清理旧数据,必然会导致OOM。不过由于我们之前已经将计数器记录在了Redis的有序集合中,因此只需要遍历它并删除指定的数据即可。
在执行清理的过程中要注意以下几点:
- 任何时候都可能会有新的计数器被添加进来
- 同一时候可能会有多个不同的清理操作
- 对于一个每天只更新一次的计数器来说,频繁扫描它的状态会浪费大量资源
- 不应尝试清理一个不包含数据的计数器
接下来简单说一下清理的逻辑:开启一个守护进程,每隔60s扫描一次计数器,对于更新频率高于扫描频率的,每次扫描后都进行清理;而对那些更新频率低于扫描频率的则可以适当减少清理次数,比如一个5min更新一次的计数器,可以每扫描5次清理一次。获取要清理的计数器后,就按照可保存的最大样本数计算记录的截止时间,将截止时间之前的记录全部清理掉。清理完毕之后检查计数器中剩余的数据,如果没有数据了,就尝试删除,不过要监视该计数器,如果有别的客户端添加数据就放弃。
def clean_counters(conn):
pipe = conn.pipeline(True)
passed = 0 # 记录清理程序的运行次数,用于同步不同频率的计数器的清理
while not QUIT:
start = time.time()
index = 0
while index < conn.zcard('known:'):
hash = conn.zrange('known:', index, index)
index += 1
if not hash:
break
# 获取计数器名称以及频率
hash = hash[0]
prec = int(hash.partition(':')[0])
# 计算计数器的清理频率
hprec = int(prec // 60) or 1
if passes % hprec:
continue
hkey = 'count:' + hash
# 计算允许存在的记录的截止时间
cutoff = time.time() - SAMPLE_COUNT * prec
# 获取计数器的时间戳
samples = map(int, conn.hkeys(hkey))
samples.sort()
# 计算清理的数量
remove = bbisect.bisect_right(samples, cutoff)
if remove:
conn.hdel(hkey, *samples[:remove])
# 如果清理完之后计数器内容为空,尝试删除
if remove == len(samples):
try:
pipe.watch(hkey)
if not pipe.hlen(hkey):
pipe.multi()
pipe.zrem('known:', hash)
pipe.execute()
index -= 1
else:
pipe.unwatch()
except redis.exceptions.WatchError:
pass
# 修改清理器的轮数
passes += 1
# 计算清理器的耗时
duration = min(int(time.time() - start + 1), 60)
# 让程序睡眠到下一个1分钟开始,如果之前已经运行了1min,就休眠1s
time.sleep(max(60 - duration, 1))存储统计数据
对于给定的上下文和类型,可以使用Redis的有序集合来存储类型的统计数据。当然这里不是为了利用它有序的特性,而是为了方便之后进行交并集运算。这里我们分析一下存储统计数据的需求:首先需要一种键值对的存储形式,可以将统计数据对应起来,其次需要能够进行交并运算方便不同统计数据间的比对,满足以上两个条件的只有有序集合。
接下来简单讲讲存储统计数据的思路:前一部分操作和log_common类似,记录当前小时和前1小时的信息。接着新建两个有序集合,一个作为最小值集合,一个作为最大值集合,然后利用适当的聚合函数计算新的最大最小值。这里专门使用并集运算的原因在于,这类值变动频率很大,自己用watch修改较为麻烦,不如交给redis的命令操作。然后对各成员进行更新即可。
def update_stats(conn, context, type, value, timeout=5):
destination = 'stats:%s:%s'%(context, type)
start_key = destination + ':start'
pipe = conn.pipeline(True)
end = time.time() + timeout
while time.time() < end:
try:
pipe.watch(start_key)
now = datetime.utcnow().timetuple()
hour_start = datetime(*now[:4]).isoformat()
existing = pipe.get(start_key)
pipe.multi()
if existing and existing < hour_start:
pipe.rename(destination, destination + ':last')
pipe.rename(start_key, destination + ':pstart')
pipe.set(start_key, hour_start)
elif not existing:
pipe.set(start_key, hour_start)
tkey1 = str(uuid.uuid4())
tkey2 = str(uuid.uuid4())
pipe.zadd(tkey1, 'min', value)
pipe.zadd(tkey2, 'max', value)
pipe.zunionstore(destination,
[destination, tkey1], aggregate='min')
pipe.zunionstore(destination,
[destination, tkey2], aggregate='max')
pipe.delete(tkey1, tkey2)
pipe.zincrby(destination, 'count')
pipe.zincrby(destination, 'sum', value)
pipe.zincrby(destination, 'sumsq', value*value)
return pipe.execute()[-3:] # 返回一些后续要用到的统计信息
except redis.exceptions.WatchError:
continue在存储了统计数据之后,我们就可以开始尝试寻找例如生成速度较慢的网页,以方便后续优化。
我们可以给每个页面都添加一个计时器来解决这个问题,但要注意的是,我们真正需要的是统计数据,是访问最慢的几个页面,因此需要实现一个既能计时,又能将计时结果存储起来的东西。
@contextlib.contextmanager
def access_time(conn, context):
start = time.time()
yield # 执行被上下文管理器包裹的代码
delta = time.time() - start
stats = update_stats(conn, context, 'AccessTime', delta)
average = stats[1] / stats[0] # 计算平均访问时长
pipe = conn.pipeline(True)
pipe.zadd('slowest:AccessTime', context, average)
pipe.zremrangebyrank('slowest:AccessTime', 0, -101) # 只保留最慢的100个界面
pipe.execute()
# 使用方式
with access_time(conn, context):
callback()统计数据不知能记录网页的加载速度,同样还可以加载模板的渲染速度,数据库的加载速度等等。除此之外,我们还可以将明显出现异常的统计数据输出到日志当中,方便进行问题的排查与优化。
查找IP属地以及国家
这一节要实现根据用户的IP定位其所在的地区。难点在于同一属地的IP地址数量很大,普通的筛选策略会消耗大量机器资源。不过同一地区的IP地址有一种特征:相比其他地区的起始IP,必然与所属地区IP的一致位数最多。因此这里可以将城市IP地址转换为分数,用有序队列存储。用户所属的地区IP就是在所有比用户IP分数小的地区IP中最大的那个。
在本例中使用散列存储城市详细信息,用有序队列存储ip分数与城市id的映射
# IP转换为分数的函数
def ip_to_score(ip_address):
score = 0
for v in ip_address.split('.'):
score = score * 256 + int(v, 10)
return score# 将城市id以及其IP地址的分数添加到有序集合
def import_ips_to_redis(conn, filename):
csv_file = csv.reader(open(filename, 'rb'))
for count, row in enumerate(csv_file):
start_ip = row[0] if row else ''
if 'i' in start_ip.lower():
continue
if '.' in start_ip:
start_ip = ip_to_score(start_ip)
elif start_ip.isdigit():
start_ip = int(start_ip, 10)
else:
continue
city_id = row[2] + '_' + str(count)
conn.zadd('ip2cityid:', city_id, start_ip)def find_city_by_ip(conn, ip_address):
if isinstance(ip_address, str):
ip_address = ip_to_score(ip_address)
# 查找所属城市的id
city_id = conn.zrevrangebyscore('ip2cityid:', ip_address, 0, start=0, num=1)
if not city_id:
return None
city_id = city_id[0].partition('_')[0]
return json.loads(conn.hget('cityid2city:', city_id))构建应用程序组件
自动补全
假设我们现在需要完成一个最近联系人的自动补全功能。这需要我们能够快速向列表中添加或是删除联系人,除此之外,这个功能不能占用太多的内存。综合以上考量,应当选择列表作为存储结构,因为列表是Redis中内存占用最小的数据结构。
在构建最近联系人阶段,主要分为以下三个步骤:
- 如果该联系人已经存在,就删除它
- 将新的最近联系人插入
- 如果最近联系人个数超出阈值就进行修剪
当需要自动补全时,从Redis中获取最近联系人列表并进行匹配,返回匹配的联系人列表。
def fetch_autocomplete_list(user, conn: redis.Redis[str], prefix):
candidates = conn.lrange('recent:' + user, 0, -1)
matches = []
for c in candidates:
if c.lower().startswith(prefix):
matches.append(c)
return matches因为在构建最近联系人列表时,我们已经有意限制了联系人数量的大小,因此这种解决方案可以取得十分优秀的效果。但如果面对的是大量数据的情况,这种方案就不太适用了。可以考虑使用带有时间戳的有序列表实现该功能。
在上面的例子中,我们的解决思路是直接从Redis现有列表中查找匹配的元素。但当元素数量很多时,扫描整个列表只为寻找几个匹配的记录就显得不是那么划算了。对于与时间有关的自动补全已经给出了方案,但如果只给定范围呢,例如公会成员列表又该怎么做呢?
接下来要介绍的方案的核心思路是:根据给定参数创建查找范围从而提升查找效率。
在介绍解决方案之前还要先介绍以下有序集合的一种变相用法,前文有提到过,当所有成员的分值都相同时,Redis就会根据成员字符串的ASCII码来进行排序(这里假设所有成员名称均为纯英文)。因此,如果用户给定abc开头的前缀,那就是需要查找abbz…与abd之间的所有成员,程序可以通过向Redis中插入abb{和abc{来创建出查找范围(在ASCII码中,`是首个排在a前的字符,{是首个排在z后的字符)
创建查找范围的思路:利用二分查找找到prefix末尾的前置字符,然后添加’{‘作为查找范围的起点,然后在prefix最后添加{作为终点。实际上是找到首个小于prefix,以及首个大于prefix的字符串。
valid_charater = '`abcdefghijklmnopqrstuvwxyz{'
def find_prefix_range(prefix):
pos = bisect.bisect_left(valid_charater, prefix)
suffix = valid_charater[(pos or 1) - 1]
return prefix[:-1] + suffix + '{', prefix + '{'具体查询的时候就是先向Redis插入刚刚创建的两个范围界限,在查找完成之后将它们删除。考虑到同一时间可能会有多个客户端尝试查询,在删除时需要开启事务,同时在返回结果时也要注意将带有{的元素清除(查询过程中可能有客户端插入了界限元素)
def auto_complete_on_prefix(conn, guide, prefix):
start, end = find_prefix_range(prefix=prefix)
identifier = str(uuid.uuid4()) # 为避免多个客户端同时查询导致起始元素和终止元素被重复添加
start += identifier
end += identifier
zset_name = "member:" + str(guide)
conn.zadd(zset_name, {start:0, end: 0})
pipeline = conn.pipeline()
while True:
try:
pipeline.watch(zset_name)
sindex = pipeline.zrank(zset_name, start)
eindex = pipeline.zrank(zset_name, end)
erange = min(sindex + 9, eindex - 2) # type: ignore
pipeline.multi()
pipeline.zrem(zset_name, start, end)
pipeline.zrange(zset_name, sindex, erange) # type: ignore
items = pipeline.execute()[-1]
break
except redis.exceptions.WatchError:
continue
return [item for item in items if '{' not in item]分布式锁
在上面的例子中,我们使用WATCH命令来保证数据的一致性。但在高负载的情况下,WATCH会导致大量的重试操作,大大拉低系统的性能。
以下列举一些并发情况下锁在不正确运行的症状:
- 持有锁的进程因为操作时间过长而导致锁被自动释放,但进程本身并不知晓这一点,甚至还可能会错误地释放掉了其他进程持有的锁。
- 一个持有锁并打算执行长时间操作的进程已经崩溃,但其他想要获取锁的进程不知道哪个进程持有着锁,也无法检测出持有锁的进程已经崩溃,只能白白地浪费时间等待锁被释放。
- 在一个进程持有的锁过期之后,其他多个进程同时尝试去获取锁,并且都获得了锁。
- 上面提到的第一种情况和第三种情况同时出现,导致有多个进程获得了锁,而每个进程都以为自己是唯一一个获得锁的进程。
下面我们来尝试以下手动实现一个简易的锁,具体思路如下:用锁名称构成命名空间,将值设置为一个uuid生成的字符串,所有涉及共享数据操作的程序都要尝试去获取指定的锁。程序会使用Redis命令setnx尝试获取锁(setnx只会在当前键没有值时将值插入进去),插入成功就代表成功获取到锁,否则就不断重试去获取锁。
def acquire_lock(conn, lockname, acquire_timeout=10):
identifier = uuid.uuid4()
end = time.time() + acquire_timeout
while time.time() < end:
if conn.setnx('lock' + lockname, identifier):
return identifier
time.sleep(.001)
return False在购买操作时,就只需要将完整的购买操作包裹在持有锁的阶段就行。其中购买操作放在try代码段内是为了保证即使程序中途异常也能保证锁最后被释放。
def purchase_item_with_lock(conn, buyerid, itemid, sellerid):
buyer = "users:%s"%buyerid
seller = "users:%s"%sellerid
item = "%s.%s"%(itemid, sellerid)
inventory = "inventory:%s"%buyerid
locked = acquire_lock(conn, market)
if not locked:
return False
pipe = conn.pipeline(True)
try:
pipe.zscore("market:", item)
pipe.hget(buyer, 'funds')
price, funds = pipe.execute()
if price is None or price > funds:
return None
pipe.hincrby(seller, 'funds', int(price))
pipe.hincrby(buyer, 'funds', int(-price))
pipe.sadd(inventory, itemid)
pipe.zrem('market:', item)
pipe.execute()
return True
finally:
release_lock(conn, market, locked)而在释放锁的时候要注意:要监视锁对应键的情况,避免某一把锁被多次释放
def release_lock(conn, lockname, identifier):
pipe = conn.pipeline(True)
lockname = 'lock:' + lockname
while True:
try:
pipe.watch(lockname)
if pipe.get(lockname) == identifier:
pipe.multi()
pipe.delete(lockname)
pipe.execute()
return True
pipe.unwatch()
break
except redis.exceptions.WatchError:
pass
return False以上的实例代码只实现了和watch同一粒度的锁,但在市场交易这种情况下,明显细粒度锁更加适合。因此只需要将传入acquire_lock中的lockname进行对应的修改就能实现粒度的更改。
dogpile效应:执行事务所需的时间越长,就会有越多待处理的事务互相重叠,这种重叠增加了执行单个事务所需的时间,并使得那些带有时间限制的事务失败的几率大幅上升,最终导致所有事务执行失败的几率和进行重试的几率都大幅地上升。典型例子就是用户等得不耐烦,重复发起请求,服务器压力飙升。
在完成了锁的创建与失效之后,就要考虑锁的超时处理了。为了保证客户端即使崩溃,也能正确释放锁,需要在其他客户端尝试请求锁且失败时,检查这一把锁的过期时间,如果没有过期就为其设置超时时间。这样,即使客户端在获取锁后,设置过期时间前崩溃了,也不会导致某一把锁从此无法获取。
def acquire_lock_with_timeout(conn, lockname, acquire_timeout=10, lock_timeout=10):
identifier = str(uuid.uuid4())
lockname = 'lock:' + lockname
lock_timeout = int(math.ceil(lock_timeout))
end = time.time() + acquire_timeout
while time.time() < end:
if conn.setnx(lockname, identifier):
conn.expire(lockname, lock_timeout)
return identifier
elif not conn.ttl(lockname):
conn.expire(lockname, lock_timeout)
time.sleep(.001)
return False利用这个新的锁,我们就可以重新实现上面的自动补全功能,每有用户需要自动补全时就直接锁定整个联系人列表,避免多个用户查询导致不断的冲突重试。
计数信号量
计数信号量用于限制一个资源最多能被多少进程同时访问,用于限定能被同时使用的资源数量。客户端获取信号量与锁的方式相同,区别在于获取不到锁会等待,而获取不到信号量则会直接返回结果。
这里使用有序队列搭配时间戳实现信号量的获取限制,程序为每一个进程生成一个唯一表示作为有序集合的成员,时间戳则为分数。若成员在指定排名之内则能够获取到信号量,否则删除自身在有序集合中的记录并返回空。同时程序在向集合中添加前会先清除过期记录。
def acquire_semaphore(conn, semname, limit, timeout=10):
identidier = str(uuid.uuid4())
now = time.time()
pipeline = conn.pipeline(True)
pipeline.zremrangebyscore(semname, '-inf', now - timeout)
pipeline.zadd(semname, identidier, now)
pipeline.zrank(semname, identidier)
if pipeline.execute()[-1] < limit:
return identidier
conn.zrem(semname, identidier)
return None
def release_semaphore(conn, semname, identifier):
return conn.zrem(semname, identifier)上面是一个非常简单的信号量实现,它的缺陷在于会默认所有发起请求的客户端的系统时间都是一样的。如果系统A比系统B快10ms,只要B在A获取信号量的10ms以内尝试获取信号量,就能窃取到A的信号量。因类似情况导致锁获取结果不同的锁或信号量,我们称他们为不公平的锁/信号量。
为了让信号量尽量公平,我们可以在程序中再添加一个计数器,每当有一个进程尝试来获取信号量就将计数器值自增并赋给对应进程。在分配信号量时,根据进程获得的计数器值来确定。
def acquire_fair_semaphore(conn, semname, limit, timeout=10):
identifier = str(uuid.uuid4())
czset = semname + ':owner'
ctr = semname + ':counter'
now = time.time()
pipeline = conn.pipeline(True)
pipeline.zremrangebyscore(semname, '-inf', now - timeout) # 将已经超时的信号量删除
pipeline.zinterstore(czset, {czset: 1, semname: 0}) # czset中只会保留还在semaphore中的记录
pipeline.incr(ctr)
counter = pipeline.execute()
pipeline.zadd(semname, identifier, now)
pipeline.zadd(czset, identifier, counter)
pipeline.zrank(czset, identifier)
if pipeline.execute()[-1] < limit:
return identifier
pipeline.zrem(semname, identifier)
pipeline.zrem(czset, identifier)
pipeline.execute()
return None
def release_fair_semaphore(conn, semname, identifier):
pipeline = conn.pipeline(True)
pipeline.zrem(semname, identifier)
pipeline.zrem(semname + ':owner', identifier)
return pipeline.execute()[0] def acquire_fair_semaphore(conn, semname, limit, timeout=10):
identifier = str(uuid.uuid4())
czset = semname + ':owner'
ctr = semname + ':counter'
now = time.time()
pipeline = conn.pipeline(True)
pipeline.zremrangebyscore(semname, '-inf', now - timeout) # 将已经超时的信号量删除
pipeline.zinterstore(czset, {czset: 1, semname: 0}) # czset中只会保留还在semaphore中的记录
pipeline.incr(ctr)
counter = pipeline.execute()
pipeline.zadd(semname, identifier, now)
pipeline.zadd(czset, identifier, counter)
pipeline.zrank(czset, identifier)
if pipeline.execute()[-1] < limit:
return identifier
pipeline.zrem(semname, identifier)
pipeline.zrem(czset, identifier)
pipeline.execute()
return None
def release_fair_semaphore(conn, semname, identifier):
pipeline = conn.pipeline(True)
pipeline.zrem(semname, identifier)
pipeline.zrem(semname + ':owner', identifier)
return pipeline.execute()[0] 由于这里我们只给信号量设置了10秒的超时时间,如果交易过程超过了10s,那就需要及时对信号量进行刷新。同时还需要注意如果信号量已经因为过期被删除,就需要拒绝调用这的请求。
在长时间使用信号量的时候,必须以合适的频率对信号量进行刷新,避免超时导致信号量被删除。
因为我们在上面区分开了超时序列和计数序列,计数序列的内容根据超时序列进行同步,因此刷新时只需要更新超时序列,确保计数序列中的对应记录不被删除即可。
def refresh_fair_semaphore(conn, semname, identifier):
if conn.zadd(semname, identifier, time.time()):
release_fair_semaphore(conn, semname, identifier)
return False
return True在完成以上功能之后,就要开始考虑消除竞争条件了。下面想象一下这样的场景:线程A首先完成了计数器的自增操作,但在线程A将自己的标识符加入有序集合之前,B完成了自增操作和添加操作,抢先一步拿到信号量。这样,虽然线程A的计数排名靠前,但因为还没有加入集合,所以信号量归B。之后信号量A将自己加入集合,检查排名发现自己满足条件,于是便能直接窃取B已经获取的信号量。而B不会收到任何提示,只会在尝试删除信号量或刷新信号量时发现。
想要解决上述问题,首先要明确问题的根源:获取信号量的过程不是原子性的,是可再分的,因此在并发环境下它就是线程不安全的。而想让一个线程不安全的操作变得线程安全,最简单的方法就是加锁,加锁是一个原子性操作,获取锁之后的操作都将是线程安全的。因此只需要在获取信号量之前,先尝试获取对应信号量的锁。
def acquire_semaphore_with_lock(conn, semname, limit, timeout=.01):
identifier = market.acquire_lock_with_timeout(conn, semname, timeout)
if identifier:
try:
return acquire_fair_semaphore(conn, semname, limit, timeout)
finally:
market.release_lock(conn, semname, identifier)任务队列
在处理请求时,对于那些执行时间较长的操作,可以放入队列,之后再对队列进行处理。这样用户可以及时得到反馈,服务器也不会因某个任务而阻塞。
任务队列的应用非常广泛,最典型的就是给用户发送邮件、验证码。
先进先出队列
这里先介绍先进先出队列,用发送邮件当作例子。由于发送邮件都有较高的延迟,且容易出现失败的情况,因此将它交给队列处理会是个好选择。将要发送的邮件信息先存储在队列当中,当要发送时,构建一个工作进程以并行的方式一次发送多封邮件。
这里使用列表来存储邮件信息,用RPUSH添加邮件,BLPOP提取出要发送的邮件。由于邮件不一定每时每刻都有,因此使用阻塞队列可以避免程序过多次重试。
def process_sold_email_queue(conn):
while not QUIT:
packed = conn.blpop(['queue'], 30)
if not packed:
continue
to_send = json.loads(packed)
try:
fetch_data_and_send_sold_email(to_send)
except EmailSenderError as e:
log_error("Failed to send")
else:
log_success("Send sold email")这是队列的最简单的一种实现方式,接下来尝试给他添加优先级。
最简单的一种方式就是用不同的队列表示不同的优先级,并按顺序将他们放入列表传递给函数。Redis的BLPOP命令会在接收到的队列列表中按顺序从最先给他提供数据的列表中抽取对象。
延迟队列
通常应用程序还会希望能让某个任务被延迟执行,例如B站发送视频设置准点发送就可以交给延迟队列来处理。这里最容易想到的一种方法就是使用有序集合存储任务的执行时间戳,定期扫描集合中有没有到期的任务要执行。
def execute_later(conn, queue, name, args, delay=0):
identifier = str(uuid.uuid4())
item = json.dump([identifier, queue, name, args])
if delay > 0:
conn.zadd('delayed:', item, time.time() + delay)
else:
conn.rpush('queue:' + queue, item)
return identifier
def poll_queue(conn):
while not QUIT:
item = conn.zrange('delayed:', 0, 0, withscores=True)
if not item or item[0][1] > time.time():
time.sleep(.01)
continue
item = item[0][0]
identifier, queue, function, args = json.loads(item)
locked = lock.acquire_lock_with_timeout(conn, identifier)
if not locked:
continue
if conn.zrem('delayed:', item):
conn.rpush('queue:' + queue, item)
lock.release_lock(conn, identifier, locked)实现时要注意的一点是,在转移任务时要给对应的任务加锁,避免某个任务被多次执行。
消息拉取
当要实现两个或多个客户端之间的相互通信时,常常使用Redis的订阅发布功能,但这种实现必须要求收发方同时在线,一旦出现连接问题,发送的消息就会丢失。此外,如果客户端速度缓慢,也会拖慢Redis的运行效率。
基于以上问题,我们可以实现一个类似邮箱的功能,即使用户不在线也不影响发送消息,连接断开也不会导致消息丢失。
具体的实现思路非常简单,用一个队列存储用户的未读消息,每当有消息要发送,就将它放入队列,用户通过请求获取存储在队列中的消息。发送方也可以通过这个队列明确消息是否已被收到。
但是只实现一个一对一的消息收发肯定是不够的,接下来我们尝试实现一个一对多的消息拉取。
首先要明确存储的信息:消息需要存储在一个队列中,通过命名空间与指定群组绑定。还需要一个集合存储群组中的成员,其分值为该成员最后阅读的消息方便后续清理所有用户都阅读过的消息。这里还另外用集合存储了用户在各个群组最后的已读消息,方便用户筛选新的消息。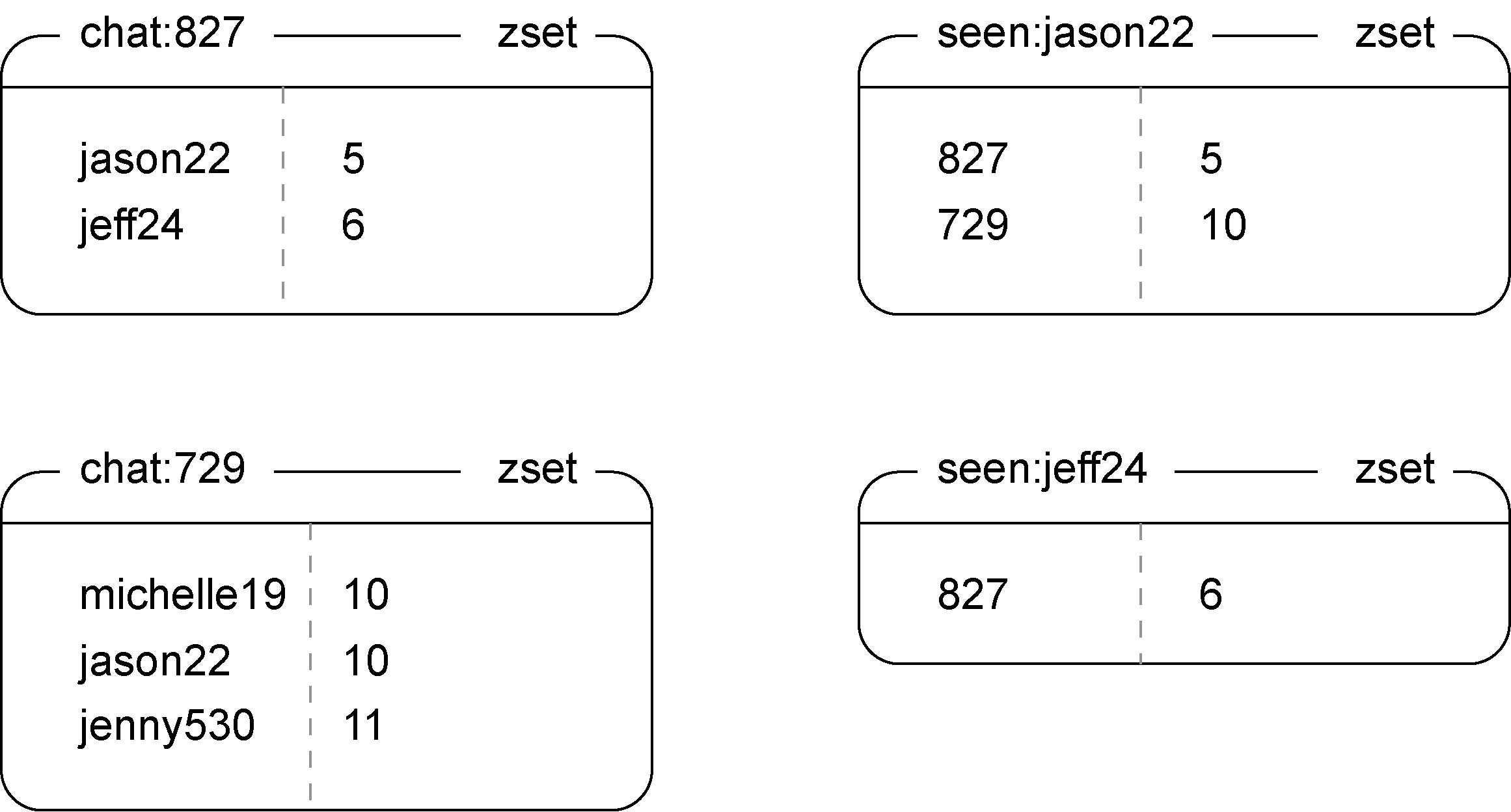
然后就是创建群组的逻辑:程序会为当前群聊生成一个编号,然后初始化对应的成员集合以及已读集合,将对应成员的已读集合中群组的分值设为0. 最后发送初始化消息.
def create_chat(conn, sender, recipients, message, chat_id=None):
chat_id = chat_id or conn.incr('ids:chat')
recipients.append(sender)
recipients_dict = dict((r, 0) for r in recipients)
pipeline = conn.pipeline(True)
pipeline.zadd('chat:' + chat_id, **recipients_dict)
for r in recipients:
pipeline.zadd('seen:' + r, chat_id, 0)
pipeline.execute()
return send_message(conn, chat_id, sender, message)
def send_message(conn, chat_id, sender, message):
identifier = lock.acquire_lock(conn, 'chat:' + chat_id)
if not identifier:
raise Exception("Couldn't get the lock")
try:
mid = conn.incr("ids:" + chat_id)
ts = time.time()
packed = json.dumps({
'id': mid,
'ts': ts,
'sender': sender,
'message': message
})
conn.zadd('msgs:' + chat_id, packed, mid)
finally:
lock.release_lock(conn, 'chat:' + chat_id, identifier)
return chat_id这里只有发送消息的部分需要注意:需要用锁来包裹发送消息的代码. 一般来说,当程序使用一个来自Redis的值去构建另一个将要被添加到Redis里面的值时,就需要使用锁或者由WATCH、MULTI和EXEC组成的事务来消除竞争条件。
接下来是获取用户消息,由于我们已经在已读集合中存储了用户读取的最后一条消息的id,可以很轻易的构建出搜索范围.用户拉取到最新消息之后,更新对应的已读列表,并根据当前群组已读消息的最小id清理被所有用户阅读过的消息.
def fetch_pending_message(conn, recipient):
# 获取当前用户所有已经阅读过的信息
seen = conn.zrange('seen:' + recipient, 0, -1, withscores=True)
pipeline = conn.pipeline(True)
# 获取用户所处群组所有的未读信息
for chat_id, seen_id in seen:
pipeline.zrangebyscore(
'msgs:' + chat_id, seen_id + 1, 'inf'
)
chat_info = zip(seen, pipeline.execute())
for i, ((chat_id, seen_id), messages) in enumerate(chat_info):
if not messages:
continue
# 反序列化所有的未读消息
messages[:] = map(json.loads, messages)
seen_id = messages[-1]['id']
# 更新用户看过的最后一条消息
conn.zadd('chat:' + chat_id, recipient, seen_id)
# 获取被所有人读过的消息的最小id
min_id = conn.zrange(
'chat:' + chat_id, 0, 0, withscores=True
)
# 更新群组中的最后一条已读消息
pipeline.zadd('seen:' + recipient, chat_id, seen_id)
if min_id:
pipeline.zremrangebyscore(
'msgs:' + chat_id, 0, min_id[0][1]
)
# 组装需要返回给用户的消息
chat_info[i] = (chat_id, messages)
pipeline.execute()
return chat_info最后是加入以及退出群组
当用户要加入群组时,需要把他添加到群组的有序集合,并更新用户已读集合.由于新加入群组必然会拉取最新的消息,因此将对应的已读id修改为最新的id.
在删除用户时,先将用户在对应群组的数据删除.然后检查群组人数,如果没有人了就直接将群组删除.如果还有人就根据最新的已读id删除所有被阅读过的消息.
def leave_chat(conn, chat_id, user):
pipeline = conn.pipeline(True)
pipeline.zrem('chat:' + chat_id, user)
pipeline.zrem('seen:' + user, chat_id)
pipeline.zcard('chat:' + chat_id)
if not pipeline.execute()[-1]:
pipeline.delete('msgs:' + chat_id)
pipeline.delete('ids:' + chat_id)
pipeline.execute()
else:
oldest = conn.zrange('chat:' + chat_id, 0, 0, withscores=True)
conn.zremrangebyscore('msgs:' + chat_id, 0, oldest[0][1])基于搜索的应用程序
使用Redis进行搜索
在讲解如何使用Redis构建搜索引擎之前,我们首先要了解一下基本的搜索原理。要想获得比扫描文档更快的搜索速度,一个显而易见的方法就是构建索引,不过通常情况下的索引都是帮助快速从文档中找到对应内容,但这里要建的索引,是根据它的内容标记对应的文档,因此称为反向索引。
在Redis中,使用集合或有序集合来存储每一个关键字对应的文档,这样在搜索的时候就能根据关键字对应的文档集合计算交并集,快速的获取查询结果。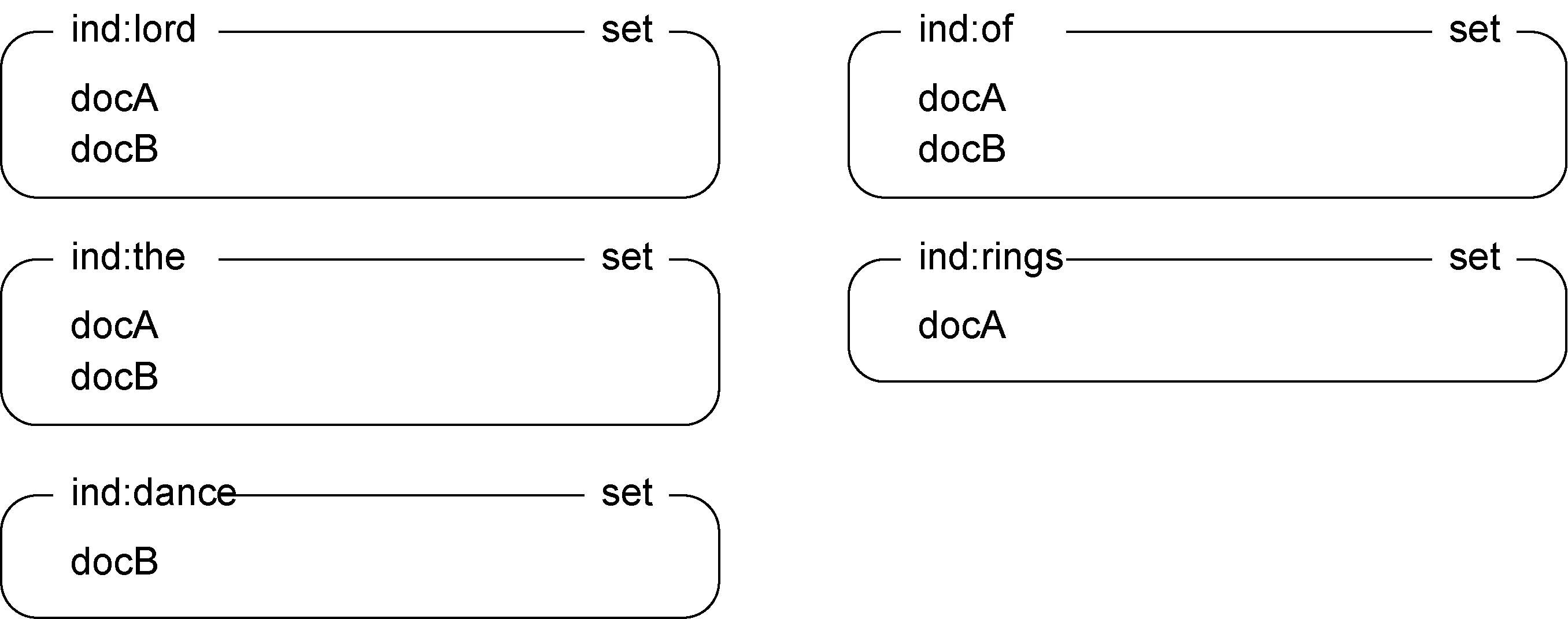
基本索引
在给程序创建索引之前,首先要对文档进行标记化(tokenization)。这里我们采取一种非常简单的标记化方法:认定单词只能由英文字母和单引号组成,并且每个单词至少有两个字符长。
标记化的一个附加步骤,就是移除内容中的非用词(stop word),这些词都不能提供有效的信息,剔除他们可以有效提升程序性能并且减小索引体积。
建立索引的基本思路就是:利用正则表达式找到匹配的单词,筛选出长度符合条件并且不属于非用词的部分,在他们对应的集合中加上文档的id
WORDS_RE = re.compile("[a-z']{2,}")
def tokenize(content):
words = set()
for match in WORDS_RE.finditer(content.lower()):
word = match.group().strip("'")
if len(word) >= 2:
words.add(word)
return words - STOP_WORDS
def index_document(conn, docid, content):
words = tokenize(content)
pipeline = conn.pipeline(True)
for word in words:
pipeline.sadd('idx:' + word, docid)
return len(pipeline.execute())如果文档的索引会变化,则可以在标记化的过程中将所有的符合条件的单词以JSON字符串格式存储进Redis中,当文档变化重新构建索引时,就可以根据里面的内容剔除掉失效的索引。
def index_document(conn, docid, content):
words_json = conn.get('words:' + docid)
words = tokenize(content)
if words_json:
old_words = json.loads(words_json)
invalid_words = old_words - words
pipeline = conn.pipeline(True)
for word in invalid_words:
pipeline.srem('idx:' + word, docid)
if not pipeline.scard('idx:' + word):
pipeline.delete('idx:' + word)
for word in words:
pipeline.sadd('idx:' + word, docid)
conn.set('words:' + docid, json.dump(words))
return len(pipeline.execute())之后要考虑的就是搜索结果的生成操作,对于简单的搜索可以直接使用交集完成。但用户有时会希望使用同义词查询或是剔除掉包含指定单词的搜索结果,这就要用到并集和差集。
def _set_common(conn, method, names, ttl=30, execute=True):
id = str(uuid.uuid4())
pipeline = conn.pipeline(True) if execute else conn
names = ['idx:' + name for name in names]
getattr(pipeline, method)('idx:' + id, *names)
pipeline.expire('idx:' + id, ttl)
if execute:
pipeline.execute()
return id
def intersect(conn, items, ttl=30, _execute=True):
return _set_common(conn, 'sinterstore', items, ttl, _execute)
def union(conn, items, ttl=30, _execute=True):
return _set_common(conn, 'sunionstore', items, ttl, _execute)
def difference(conn, items, ttl=30, _execute=True):
return _set_common(conn, 'sdiffstore', items, ttl, _execute)接下来一步就是进行语法分析,这里规定对于以+为前缀的单词,表示这一个单词是之前单词的同义词,以-为前缀的单词表示要去掉包含该单词的搜索结果。
def parse(query):
unwanted = set()
all = []
current = set()
for match in QUERY_RE.finditer(query.lower()):
word = match.group()
prefix = word[:1]
if prefix in '+-':
word = word[1:]
else:
prefix = None
word = word.strip("'")
if len(word) < 2 or word in STOP_WORDS:
continue
if prefix == '-':
unwanted.add(word)
continue
if current and not prefix:
all.append(list(current))
current = set()
current.add(word)
if current:
all.append(list(current))
return all, list(unwanted)最后就是实现查找功能了,具体思路是:对于每一个同义词列表都进行并运算后将其对应的临时集合id添加到接下来的运算集合中,对于只有一个元素的集合则直接添加。将收集到的运算集合进行交集运算获得结果,如果没有要提出的关键字就直接返回,如果有则再将他们剔除
def parse_and_search(conn, query, ttl=30):
all, unwanted = parse(query)
if not all:
return None
to_intersect = []
for syn in all:
if len(syn) > 1:
to_intersect.append(union(conn, syn, ttl))
else:
to_intersect.append(syn[0])
if len(to_intersect) > 1:
intersect_result = intersect(conn, to_intersect, ttl)
else:
intersect_result = to_intersect[0]
if unwanted:
unwanted.insert(0, intersect_result)
return difference(conn, unwanted, ttl)
return intersect_result不过单纯找出搜索结果还不够,最好可以根据关联度对搜索结果进行排序,方便用户查找需要的消息。这里使用最简单的一种关联度排序方式:根据文章的最后更新时间。
关联度排序的实现可以使用Redis的sort函数,它可以根据外部数据对结果进行排序。
对于排序生成的结果可以让他们的生存时间更长一点
def search_and_sort(conn, query, id=None, ttl=300, sort='-updated', start=0, num=20):
desc = sort.startswith('-')
sort = sort.lstrip('-')
by = 'kd:doc:*->' + sort
alpha = sort not in ('updated', 'id', 'created')
if id and not conn.expire(id, ttl): # 如果用户提供了id,并且还没有过期就延长它的生存周期
id = None
if not id: # 如果没有提供,就代表还没完成搜索
id = parse_and_search(conn, query, ttl)
pipeline = conn.pipeline(True)
pipeline.scard('idx:' + id)
pipeline.sort('idx:' + id, by=by, alpha=alpha, desc=desc, start=start, num=num)
results = pipeline.execute()
return results[0], results[1], id有序索引
但在真实的业务场景中,根据单一的指标进行关联度分析显然是不合理的,我们需要一种能够将各种指标按照指定的权重结合起来计算关联度的方法。
Redis的ZINTERSTORE命令可以将传入的集合,按照指定的权重进行聚合,这里我们让它按照计算各种指标的权重并相加。为了达成这个目的,还需要添加两个集合,一个统计投票数,一个统计更新时间。(ZINTERSTORE也可以接收普通集合,他们元素的分值都设为1)
解决思路:
首先,如果程序接收到id并且该id没有过期,说明不需要再额外做一次查询,只需要将id对应的键的生命周期延长。
如果没有id或id过期,则再进行一次基本查询,获取到临时集合的id
接下来设置各个集合的权重,id对应的集合权重为0,因为该集合只负责与投票集合和更新集合匹配,投票集合以及更新集合的权重根据参数配置。之后将他们交给计算方法
def search_and_zsort(conn, query, id=None, ttl=300, update=1, vote=1, start=0, num=20, desc=True): if id and not conn.expire(id, ttl): id = None if not id: id = parse_and_search(conn, query, ttl=ttl) scored_search = { id: 0, 'sort:update': update, 'sort:votes': vote } id = zintersect(conn, scored_search, ttl) pipeline = conn.pipeline(True) if desc: pipeline.zrevrange('idx:' + id, start, start + num - 1) else: pipeline.zrange('idx:' + id, start, start + num - 1) results = pipeline.execute() return results[0], results[1], id计算方法接收到参数后,将他们权重表中的键修改为Redis中对应的键,之后调用对应的方法
def _zset_common(conn, method, scores, ttl=30, **kw): id = str(uuid.uuid4()) execute = kw.pop('_execute', True) pipeline = conn.pipeline(True) if execute else conn for key in scores.keys(): scores['idx:' + key] = scores.pop(key) getattr(pipeline, method)('idx:' + id, scores, **kw) pipeline.expire('idx:' + id, ttl) if execute: pipeline.execute() return id
def zintersect(conn, items, ttl=30, **kw):
return _zset_common(conn, ‘zinterstore’, dict(items), ttl, **kw)
def zunion(conn, items, ttl=30, **kw):
return _zset_common(conn, ‘zunionstore’, dict(items), ttl, **kw)
如果要让Redis实现非数值排序,那要做的工作显然就是将对应的非数值按照一定规则转换为数值。当我们想要进行字符串排序时,可以将每个字母转换成对应的数字,ASCII码显然是个不错的选择。不过这也同样有所限制,Redis的有序集合的分值使用64位浮点型存储,最多处理8个字符。这里的例子只进行前6位字母的排序。
```python
def string_to_score(string, ignore_case=False):
if ignore_case:
string = string.lower()
pieces = map(ord, string[:6])
while len(pieces) < 6:
pieces.append(-1)
score = 0
for piece in pieces:
score = score * 257 + piece + 1
return score * 2 + (len(string) > 6)有了将字符串转换为分值的启发,之前的自动补全功能也能进行进一步优化。如果我们将人名信息转换为分值,那么在查询时就不必再建立查找范围,只需将原先用于建立查找范围的边界值转换为分值,然后调用zrangebyscore即可。
此外,如果我们修改字符串转换的规则,例如,只考虑小写字母的匹配,那么每一个字符只需要使用5个位即可完成存储,这样就能容纳下更多的字符进行前缀匹配。
职位搜索
本节将着手解决职位搜索问题,更好的找到匹配求职者现有技能的职位。
首先最简单的一种实现方式就是将职位所需的技能要求都添加到对应的集合中,当求职者要查看是否匹配时,就将职位的技能集合和求职者的技能集合进行差集计算。
def add_job(conn, job_id, required_skills):
conn.sadd('job:' + job_id, *required_skills)
def is_quialified(conn, job_id, candidate_skills):
temp = str(uuid.uuid4())
pipeline = conn.pipeline(True)
pipeline.sadd(temp, *candidate_skills)
pipeline.expire(temp, 5)
pipeline.sdiff('job:' + job_id, temp)
return not pipeline.execute()[-1]这个实现方法非常简单,但是缺点也很明显,它需要对每个职位都进行单独的检查,十分影响后续的性能扩展。
除了这种最简单的搜索方法之外,还可以通过搜索的方式查找到合适的职位,不过他对Redis数据结构的操作和平常的方法并不一样。
首先我们像建立反向索引一样,在每一个技能集合下存储需要这个技能的职位id,然后将每个职位需要的技能数存储在一个有序集合中。当程序接收到用户传入的技能组后,它会将涉及的技能集合进行并集运算,由于集合的分值默认位1,因此这样生成的结果就是职位id与求职者满足该职位要求的技能的数量。然后再将这个临时集合与存储了职位要求技能数的结合进行交集运算,一个集合的权重为1,另一个为-1,最后生成的结果中,分数为0的职位就是满足要求的职位。
def index_job(conn, job_id, skills):
pipeline = conn.pipeline(True)
for skill in skills:
pipeline.sadd('idx:skill:' + skill, job_id)
pipeline.zadd('idx:jobs:req', job_id, len(skills))
pipeline.execute()
def find_jobs(conn, candidate_skills):
skills = {}
for skill in set(candidate_skills):
skills['skill:' + skill] = 1
job_scores = search.zunion(conn, skills)
final_result = search.zintersect(conn, {job_scores:-1, 'jobs:req':1})
return conn.zrangebyscore('idx:' + final_result, 0, 0)如果还要加上对技能熟练度的考虑,可以用有序集合存储技能要求,并根据熟练度要求给每个职位赋予相应的分值。然后在计算用户得分时也根据熟练度计算分值,最后结果 >0 的都是满足要求的职位。
构建简单的社交网站
用户和状态
对于用户信息,通常都是使用散列来存储。创建用户的整个过程非常简单,但是需要注意的是,为了防止多个请求注册相同用户名导致唯一性被破坏,在开始执行创建操作之前,需要将要注册的用户名锁起来(这里用户名就是一种资源)。除此之外还要注意用户的敏感信息不能存储在该散列中,因为程序会频繁取出这个散列用于响应,这些信息应当存储在其他地方。
def create_user(conn, login, name):
llogin = login.lower()
# 尝试获取用户名对应的锁
lock = acquire_lock_with_timeout(conn, "user:" + llogin, 1)
# 如果获取失败,代表有别的线程在创建该用户名的角色
if not lock:
return None
# 如果该用户名已被使用过,创建失败
if conn.hget(conn, "user:" + llogin):
release_lock(conn, "user:" + llogin, lock)
return None
id = conn.incr("user:id:")
pipeline = conn.pipeline(True)
pipeline.hset("users:", llogin, id)
pipeline.hmset("users:%s"%id, {
'login': login,
'id': id,
'name': name,
'followers': 0,
'following': 0,
'posts': 0,
'signup': time.time()
})
pipeline.execute()
release_lock(conn, "user:" + llogin, lock)
return id创建用户状态也非常简单,这里不多赘述
def create_status(conn, uid, message, **data):
pipeline = conn.pipeline(True)
pipeline.hget('user:%s'%uid, 'login')
pipeline.incr('status:id:')
login, id = pipeline.execute()
if not login:
return None
data.update({
'message': message,
'posted': time.time(),
'id': id,
'uid': uid,
'login': login
})
pipeline.hmset('status:%s'%id, data)
pipeline.hincrby('user:%s'%uid, 'posts')
pipeline.execute()
return id主页时间线
在使用B站等应用时,一般都会有动态功能,也就是主页时间线。他记录了一段时间里关注对象发布的动态消息。由于主页时间线很多时候是用户进入应用的入口,因此对应的信息必须简单易获取。
这里使用一个有序队列来存储状态消息id和它的发布时间戳。在查询的时候按照从新到旧的顺序查找状态信息id,并根据获取到的id取得状态信息数据。
def get_status_message(conn, uid, timeline='home:', page=1, count=30):
statuses = conn.zrevrange('%s%s'%(timeline, uid), (page-1)*count, page*count-1)
pipeline = conn.pipeline(True)
for id in statuses:
pipeline.hgetall('status:%s'%id)
# 用过滤器过滤掉已被删除的部分
return filter(None, pipeline.execute())上面的代码除了查询主页时间线意外,还可以查询到个人时间线(只包含个人动态),只需要修改timeline即可。
当然以上的操作都只设计查询,真正的应用还需要在关注和取消关注时维护对应的时间线集合。这里使用两个有序集合存储用户的关注列表和被关注列表。存储用户id以及对应的关注/被关注时间戳。
当用户执行关注操作时,除了将用户id存入二人的关注列表和被关注列表之外,还需要将被关注者的一部分状态信息更新到关注者的主页时间线当中。
HOME_TIMELINE_SIZE = 1000
def follow_user(conn, uid, other_id):
fkey1 = 'following:%s'%uid
fkey2 = 'followers:%s'%other_id
if conn.zscore(fkey1, other_id):
return None
now = time.time()
pipeline = conn.pipeline(True)
pipeline.zadd(fkey1, other_id, now)
pipeline.zadd(fkey2, uid, now)
pipeline.zrevrange('profile:%s'%other_id, 0, HOME_TIMELINE_SIZE - 1, withscores=True)
following, followers, status_and_score = pipeline.execute[-3:]
pipeline.hincrby('user:%s'%uid, 'following', int(following))
pipeline.hincrby('user:%s'%other_id, 'followers', int(followers))
if status_and_score:
pipeline.zadd('home:%s'%uid, **dict(status_and_score))
pipeline.zremrangebyrank('home:%s'%uid, 0, -HOME_TIMELINE_SIZE - 1)
pipeline.execute()
return True在将关注者的主页时间线更新之后,还需要将他们的大小缩减到阈值,避免OOM。
取关的操作流程刚好与关注的流程相反,只需要将用户id从关注者列表和被关注者列表中移除,然后在主页时间线中修改对应的信息即可。
def unfollow_user(conn, uid, other_uid):
fkey1 = 'following:%s'%uid
fkey2 = 'followers:%s'%other_uid
if not conn.zscore(fkey1, other_uid):
return None
pipeline = conn.pipeline(True)
pipeline.zrem(fkey1, other_uid)
pipeline.zrem(fkey2, uid)
pipeline.zrevrange('profile:%s'%other_uid, 0, HOME_TIMELINE_SIZE - 1)
following, followers, statuses = pipeline.execute()[-3:]
pipeline.hincrby('user:%s'%uid, 'following', int(following))
pipeline.hincrby('user:%s'%other_uid, 'followers', int(followers))
if statuses:
pipeline.zrem('home:%s'%uid, *statuses)
pipeline.execute()
return True如果想要在取消关注后重新填充,只需在取关后记录下本次在主页时间线中删除的记录数,然后去用户关注的博主的个人时间线中获取对应数量的记录填充进来即可,最后将大小修建为阈值。
不过用户在取关之后肯定希望立即得到反馈,因此,重新填充的工作可以交给延迟队列来进行。
状态信息的发布与删除
前面只讲了程序如何获取状态信息,接下来要做的就是添加状态信息的发布与删除。当消息发布时,对应的id应当被推送的关注者的主页时间线当中。如果关注者的数量较少,这个操作可以被立即执行,但如果关注者的数量非常庞大,那立即更新就会导致很长的等待时间,这里可以使用延迟队列来确保函数最终能够以合理的等待时间返回。
def post_status(conn, uid, message, **data):
id = create_status(conn, uid, message, **data)
if not id:
return None
posted = conn.hget('status:%s'%id, 'posted')
if not posted:
return None
post = {str(id): float(posted)}
conn.zadd('profile:%s'%uid, **post)
syndicate_status(conn, uid, post)
return id
POST_PER_PASS = 1000
def syndicate_status(conn, uid, post, start):
# 获取最多1000个关注者
followers = conn.zrangebyscore('followers:%s'%uid, start, 'inf', start=0, num=POST_PER_PASS, withscores=True)
pipeline = conn.pipeline(False)
# 更新这些关注者的主页时间线
# 遍历的同时更新start变量,作为下一次的起始
for follower, start in followers:
pipeline.zadd('home:%s'%follower, **post)
# 修剪主页时间线,防止它长度超过阈值
pipeline.zremrangebyrank('home:%s'%follower, 0, -HOME_TIMELINE_SIZE-1)
pipeline.execute()
# 如果关注者数量很大,就将它推给延迟队列
if len(followers) >= POST_PER_PASS:
execute_later(conn, 'default', 'syndicate_status',[conn, uid, post, start])而删除的操作相对来说就非常简单了,因为在获取状态消息时使用了filter过滤掉已经被删除的信息,因此只需要删除掉状态消息在散列中的记录,它就不会在任何时间线中出现了。具体的流程和别的删除操作没太大区别,同样是对被删除的记录加锁然后修改发布者的数据信息。
def delete_status(conn, uid, status_id):
key = 'status:%s'%status_id
lock = acquire_lock_with_timeout(conn, key, 1)
if not lock:
return None
if conn.hget(key, 'uid') != str(uid):
release_lock(conn, key, lock)
return None
pipeline = conn.pipeline(True)
pipeline.delete(key)
pipeline.zrem('profile:%s'%uid, status_id)
pipeline.zrem('home:%s'%uid, status_id)
pipeline.hincrby('user:%s'%uid, 'posts', -1)
pipeline.execute()
release_lock(conn, key, lock)
return True这样的删除虽然简单,但是被删除的消息id依旧存储在用户的主页时间线里,时间久了会积压大量的无用数据,因此还需要对这些数据进行清理。
具体操作也非常简单,只需要通过消息散列获取对应的发布者id,得到关注者列表然后依据列表大小进行删除即可(分批/不分批)
流API
在开发网站的过程中,我们可能希望收集一些网站中发生的事件方便后续的优化与数据分析。最容易想到的实现方法就是专门执行一些调用来收集这些信息或是在所有执行操作的函数内部添加这部分功能。
不过在本节,我们使用另一种方法来实现这类功能:构建一些函数来广播事件,然后由负责数据分析的事件监听器来接收并处理。
流API与其他功能最大的区别就是,一般的操作都需要尽快完成并返回,而流API则需要在一定时间内持续返回结果。也就是说,随着事件推移,流API逐渐会构成一个由事件组成的序列,来让网站和客户端了解到在网站中发生的事情。
在接下来的例子中我们将让流API监控消息的创建与删除,由于流API不是像处理普通请求一样,一次性返回完整的所有数据,因此需要使用分块技术让HTTP服务器可以生成并发送增量式数据。
服务器
首先第一步就是为流API创建一个服务器,这个服务器可以为每一个请求都开启一个线程进行处理。在服务器代码中体现的逻辑非常简单,就是先标识客户端接着验证请求是否合法然后交给过滤器进行过滤操作。
class StreamingAPIServer(socketserver.ThreadingMixIn, http.server.HTTPServer):
deamon_threads = True
class StreamingAPIRequestHandler(http.server.BaseHTTPRequestHandler):
def do_GET(self):
parse_identifier(self)
if self.path != '/statuses/sample.json':
return self.send_error(404)
process_filter(self)
def do_POST(self):
parse_identifier(self)
if self.path != '/statuses/filter.json':
return self.send_error(404)
process_filter(self)接下来这部分是处理语法分析的函数
def parse_identifier(handler):
# 将标识符和查询参数设为预留值
handler.identifier = None
handler.query = {}
if '?' in handler.path:
# 取出路径中包含查询参数的部分并更新路径
handler.path, _, query = handler.path.partition('?')
# 通过语法分析获取查询参数
handler.query = urlparse.parse_qs(query)
# 获取identifier的查询参数列表
identifier = handler.query.get('identifier') or [None]
handler.identifier = identifier[0]之后是校验请求并向客户端发送流数据,这个函数的基本构思是确保服务器取得客户端的标识符,并且成功获取请求指定的过滤参数。最终按照分块的方式将数据传递给客户端
FILTERS = {'track', 'filter', 'location'}
def process_filters(handler):
id = handler.identifier
if not id:
return handler.send_error(401, 'identifier missing')
method = handler.path.rsplit('/')[-1].split('.')[0]
name = None
args = None
if method == 'filter':
data = cgi.FieldStorage(
fp=handler.rfile,
headers=handler.headers,
environ={'REQUEST_METHOD':'POST',
'CONTENT_TYPE': handler.headers['Content-Type']}
)
for name in data:
if name in FILTERS:
args = data.getfirst(name).lower().split(',')
break
if not args:
return handler.send_error(401, "no filter provided")
else:
args = handler.query
handler.send_response(200)
handler.send_header('Transfer-Encoding', 'chunked')
handler.end_headers()
quit = [False]
for item in filter_content(id, method, name, args, quit):
try:
handler.wfile.write('%X\r\n%s\r\n'%(len(item), item))
except socket.error:
quit[0] = True
if not quit[0]:
handler.wfile.write('0\r\n\r\n')对流消息进行过滤
一个大型的网站每时每刻都有大量的事件发生,如果将这些事件全部传输给客户端会带来大量的带宽消耗,因此让服务器只发送客户端需要的消息就非常重要了。
这里我们使用Redis的发布-订阅机制来实现部分功能:当用户发送一条消息时,将其发送给某一个频道,各个过滤器通过订阅那个频道来接收消息并当消息匹配时回传给客户端。
def create_status(conn, uid, message, **data):
pipeline = conn.pipeline(True)
pipeline.hget('user:%s'%uid, 'login')
pipeline.incr('status:id:')
login, id = pipeline.execute()
if not login:
return None
data.update({
'message': message,
'posted': time.time(),
'id': id,
'uid': uid,
'login': login
})
pipeline.hmset('status:%s'%id, data)
pipeline.hincrby('user:%s'%uid, 'posts')
# 新添加的代码,用于向过滤器发送消息
pipeline.publish('streaming:status:', json.dumps(data))
pipeline.execute()
return id而当要删除某条消息时,则要向频道中传输一条该消息已被删除的消息。如果程序本身就纪录了发送消息的状态,那这一步就不需要了,不过这样做带来的是管理上的难度。如果我们通过传递删除消息给过滤器,就可以避免存储状态信息,简化了服务器设计且降低了内存占用。
def delete_status(conn, uid, status_id):
key = 'status:%s'%status_id
lock = acquire_lock_with_timeout(conn, key, 1)
if not lock:
return None
if conn.hget(key, 'uid') != str(uid):
release_lock(conn, key, lock)
return None
pipeline = conn.pipeline(True)
# 新增的代码,将已经删除了的消息发送给指定频道
status = conn.hgetall(key)
status['deleted'] = True
pipeline.publish('streaming:status', json.dumps(status))
pipeline.delete(key)
pipeline.zrem('profile:%s'%uid, status_id)
pipeline.zrem('home:%s'%uid, status_id)
pipeline.hincrby('user:%s'%uid, 'posts', -1)
pipeline.execute()
release_lock(conn, key, lock)
return True处理好了发布消息的函数,接下来就要添加负责接收和处理流消息的函数了
首先创建一个过滤器来判断内容是否要发送给客户端。接着从频道中获取消息并取出消息状态;之后检查消息是否匹配,状态是否正常,如果消息已被删除则给客户端返回一个消息已删除的信息否则就返回整个消息。
@redis_connection('social-netword')
def filter_content(conn, id, method, name, args, quit):
match = create_filter(id, method, name, args)
pubsub = conn.pubsub()
pubsub.subscribe(['streaming:status:'])
for item in pubsub.listen():
message = item['data']
decoded = json.loads(message)
if match(decoded):
if decoded.get('deleted'):
yield json.dumps({
'id': decoded['id'],
'deleted': True
})
else:
yield message
if quit[0]:
break
pubsub.reset()之后具体的过滤器创建就不多赘述了,可以根据自己的业务要求创建需要的过滤器。
降低内存占用
短结构
对于长度比较短的结构,Redis提供了一系列配置选项,可以让它以更节约空间的方式存储长度较短的结构。
在列表、散列和有序集合的长度较短或者体积较小的时候,Redis可以选择使用一种名为_压缩列表_(ziplist)的紧凑存储方式来存储这些结构。压缩列表是列表、散列和有序集合这3种不同类型的对象的一种非结构化(unstructured)表示。
压缩列表会以序列化的方式存储数据,每次读取都要对数据进行解码,每次写入也要进行局部的重新编码,并且可能需要对内存里的数据进行移动。
压缩列表表示
在讲压缩列表之前,我们先看一下Redis列表的存储方式。
Redis在存储长列表时,会存储一个指向前面节点和后面节点的指针。在包含字符串的指针中,又会存储当前节点的字符串长度以及剩余可用的字节数量。也就是说每个节点都需要额外存储3个指针,两个整数,以及字符串内的一个额外字节,算下来每个节点都至少需要21个字节的额外开销。
而压缩列表则是用节点组成的序列,每个节点都用两个长度值和一个字符串组成。第一个长度值记录的是前一个节点的长度,这个长度值会被用来进行从后向前的遍历,第二个长度值记录了当前节点的长度,最后则是真正的字符串。压缩列表就是这样通过避免存储额外的元数据和指针来减少存储空间的占用。
Redis配置文件的设置
list-max-ziplist-entries 512
list-max-ziplist-value 64
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
zset-max-ziplist-entries 128
zset-max-ziplist-value 64entries表示列表散列和有序集合在被编码为压缩列表的情况下允许包含的最大元素
value表示压缩列表每个节点的最大体积是多少个字节
集合的整数集合编码
对于体积较小,并且成员都可以被解释为十进制整数的集合,Redis就会以有序数组的方式存储集合,这种存储方式又称为整数集合。
配置文件设置
set-max-intset-entries 512短结构存在的性能问题
前面提到,Redis存储短结构时,是将他们序列化后存储在内存中,这就代表他在读写时多了编解码操作,因此当短结构的体积很大时,它反而会带来巨大的性能问题。
而对于整数集合来说,虽然它本身不需要序列化存储,但每一次插入都需要进行数据的移动,当数据量非常大时,这个操作就会很消耗时间。
分片结构
分片:本质上是基于某些简单的规则将数据划分为更小的部分,然后根据数据所属的部分来决定将数据发送到哪个位置上面。
ps:分片对有序集合来说提升并不明显,因为有序集合需要等待所有的分片完成操作之后才能获得结果。
分片式散列
对散列进行分片首先需要选择一个方法来对数据进行划分。因为散列本身就存储着一些键,所以程序在对键进行划分的时候,可以把散列存储的键用作其中一个信息源,并使用散列函数为键计算出一个数字散列值。然后程序会根据需要存储的键的总数量以及每个分片需要存储的键数量,计算出所需的分片数量,并使用这个分片数量和键的散列值来决定应该把键存储到哪个分片里面。
分片函数:
def shard_key(base, key, total_elements, shard_size):
if isinstance(key, (int)) or key.isdigit():
shard_id = int(str(key), 10) // shard_size
else:
shards = 2 * total_elements // shard_size
shard_id = binascii.crc32(key) % shards
return "%s:%s"%(base, shard_id)上面例子中的分片函数需要用户传入基础散列的名字,将要被存储到分片散列里的键,预计的元素总数量以及请求的分片数量
在对非数字键进行分片时,需要total_elements和shard_size用于计算实际所需的分片总数量。因此这两个参数都应尽量不发生变化,即使真的需要修改,也要使用resharding(重新分片)来讲数据从旧分片迁移到新分片。
分片的使用
def shard_hset(conn, base, key, value, total_elements, shard_size):
shard = shard_key(base, key, total_elements, shard_size)
return conn.hset(shard, key, value)
def shard_hget(conn, base, key, total_elements, shard_size):
shard = shard_key(base, key, total_elements, shard_size)
return conn.hget(shard, key)分片集合
之前我们提到过计算网站唯一访客的数量,这里提一下另一种做法:使用集合存储到访用户的id,但如果单纯使用集合存储,那往往会导致最终集合的体积异常庞大,这时就可以使用到分片技术了。
只要使用上一节讲的分片方法,我们就能很轻易的实现分片集合,但由于我们存储的是UUID,它的过长的长度会导致我们无法享受到整数集合带来的好处。因此,我们可以将UUID的前15个十六进制数字用作分片的键。
使用UUID的前15个十六进制数字可以大幅减少内存的占用,同时让Redis能够以整数集合的方式存储。
具体实现
思路:根据用户的会话id生成传入Redis的id,并获取预期的访客数量,交给分片集合函数进行处理。如果成功添加,就将当天的访客数+1
def shard_sadd(conn, base, member, total_elements, shard_size):
shard = shard_key(base, 'x' + str(member), total_elements, shard_size)
return conn.sadd(shard, member)
SHARD_SIZE = 512
def count_visit(conn, session_id):
today = date.today()
key = 'unique:%s'%today.isoformat()
expected = get_expected(conn, key, today)
id = int(session_id.replace('-', '')[:15], 16)
if shard_sadd(conn, key, id, expected, SHARD_SIZE):
conn.incr(key)
DAILY_EXPECTED = 1000000
EXPECTED = {}
def get_expected(conn, key, today):
if key in DAILY_EXPECTED:
return EXPECTED[key]
exkey = key + ':expected'
expected = conn.get(exkey)
if not expected:
yesterday = (today - timedelta(days=1)).isoformat()
expected = conn.get('unique:%s'%yesterday)
expected = int(expected or DAILY_EXPECTED)
expected = 2**int(math.ceil(math.log(expected*1.5, 2)))
if not conn.setnx(exkey, expected):
expected = conn.get(exkey)
EXPECTED[key] = int(expected)
return EXPECTED[key]扩展Redis
扩展读性能
在开始扩展性能之前,先回顾一下可以提高性能的几个途径:
- 使用上一章提到的短结构时,确保压缩列表的最大长度不会太大以至于影响性能。
- 根据程序需要执行的查询类型,选择能为这种查询提供最好性能的结构。
- 在将大体积的对象缓存到Redis里之前,考虑先对它进行压缩以减少读取和写入对象时所需的网络带宽。
- 使用流水线和连接池。
接下来就可以开始考虑提升Redis读取能力的方法了,最容易想到的就是添加只读从服务器。
在使用只读从服务器时,必须牢记只可以对Redis主服务器进行写入。
在使用多个Redis从服务器处理查询时可能会遇到的最棘手的问题就是主服务器临时下线或者永久下线。所以每当有从服务器尝试与主服务器建立连接时,主服务器都会为从服务器创建一个快照,如果有多个从服务器建立连接,他们最后都会收到同一个快照。这大幅减少了创建快照的工作负担。
不过大量的发送快照副本也会大量消耗主服务器的带宽,导致主服务器延迟变高,甚至主服务器已经建立的连接断开。
因此,想要解决服务器重同步问题的办法之一,就是减少主服务器传送给从服务器的数据量。而最简单的实现方法,就是添加一个中间层,让中间层的服务器负责转发数据副本。
中间层可以有效分担主服务器传输数据副本的压力,不过这也导致了复杂的网络拓扑结构,增加了处理故障的难度。
除了添加服务器群组之外,解决重同步的另一个方向就是对网络连接进行压缩,从而减少需要传送的数据量。
[!note]+ 加密和压缩开销
使用带压缩的SSH隧道可以有效减少网络负载。
SSH隧道:在SSH客户端与SSH服务端之间建立一个隧道,将网络数据通过该隧道转发至指定端口,从而进行网络通信。SSH隧道自动提供了相应的加密及解密服务,保证了数据传输的安全性。
SSH的加密算法并不会占用很多的处理器资源,一般来说会将SSH压缩的等级控制在5级以下。因为5级压缩可以在1级压缩的基础上,将数据的总体积减少10%~20%,并且只需要相当于1级压缩2~3倍的处理时间。
[!note]+ 使用OPENVPN进行压缩
初看上去,使用AES加密和lzo压缩的OpenVPN似乎是一个绝妙的现成解决方案,跟SSH需要使用第三方脚本才能进行自动重连接相比,OpenVPN不仅提供加密和压缩功能,而且还具有对用户透明的重连接功能。遗憾的是,我能够找到的大部分信息都显示OpenVPN在开启lzo压缩之后,对于10兆网络连接的性能提升只有25%~30%,而对于速度更快的连接,lzo压缩不会给性能带来任何提升。
[!def]+ Sentinal
Redis的哨兵可以配合Redis的复制功能使用,并对下线的主服务器进行故障转移。哨兵会监视系一列主服务器以及这些主服务器的从服务器。
通过向主服务器发送PUBLISH和SUBSCRIBE命令(确认主服务器能够正确收发消息),并向主从服务器发送PING命令,各个哨兵进程可以自主识别可用的从服务器和其他的哨兵。当主服务器失效时,监视该主服务器的所有哨兵会基于彼此共有的信息选出一个哨兵,并选出一个新的主服务器。选出的哨兵会负责让剩余的从服务器去复制这个新的主服务器。
扩展写性能
在扩展写性能之前,我们同样需要检查是否已经尽一切可能降低了内存占用,并且是否尽可能介绍了需要写入的数据量。
- 尽可能减少程序需要读取的数据量
- 将无关的功能迁移至其他服务器
- 在对Redis进行写入之前,尝试在本地内存中对将要写入的数据进行聚合运算
- 使用锁去替换可能会给速度带来限制的
WATCH/MULTI/EXEC事务 - 降低命令长度
如果以上的操作都基本已经做到极限了,就代表达到了单台服务器的性能瓶颈。这时就可以将数据分片到多台机器上了。
[!tip]+ 预先分片
在为了应对未来可能出现的流量增长而对系统进行预先分片的时候,我们可能会陷入这样一种处境:目前拥有的数据实在太少,按照预先分片方法计算出的机器数量去存储这些数据只会得不偿失。为了能够如常地对数据进行分割,我们可以在单台机器上面运行多个Redis服务器,并将每个服务器用作一个分片;或者使用单个Redis服务器上的多个Redis数据库。然后以此为起点,复制和配置管理方法,将数据迁移到多台机器上面。
分片配置信息处理
由于各个分片分布在不同的机器上,因此需要一个函数来根据分片动态获取对应的Redis连接。
def get_redis_connection(component, wait=1):
key = 'config:redis:' + component
# 获取旧配置
old_config = CONFIGS.get(key, object())
# 获取新配置
config = get_config(
config_connection, 'redis', component, wait)
# 如果新旧配置不同,就创建一个新的连接
if config != old_config:
REDIS_CONNECTIONS[key] = redis.Redis(**config)
return REDIS_CONNECTIONS.get(key)
def get_sharded_connection(component, key, shard_count, wait=1):
shard = shard_key(component, 'x'+str(key), shard_count, 2)
return get_redis_connection(shard, wait)创建分片服务器连接装饰器
接下来我们就需要使用get_sharded_connection写出一个能够自动创建分片连接,并将分片连接传递给底层函数的装饰器。
def sharded_connection(component, shard_count, wait=1):
def wrapper(function):
@functools.wraps(function)
def call(key, *args, **kwargs):
conn = get_sharded_connection(
component, key, shard_count, wait
)
return function(conn, key, *args, **kwargs)
return call
return wrapper这个包装器可以实现在不修改count_visit()的情况下直接对它进行封装。但要注意的是,由于count_visit需要维持聚合计数信息,而获取这些信息需要通过get_expected,这个函数没有必要分片并且会在不同的时期被不同的用户使用,所以需要对它进行非分片连接。
@sharded_connection('unique', 16)
def count_visit(conn, session_id):
today = date.today()
key = 'unique:%s'%today.isoformat()
conn2, expected = get_expected(key, today)
id = int(session_id.replace('-', '')[:15], 16)
if shard.shard_sadd(conn, key, id, expected, shard.SHARD_SIZE):
conn2.incr(key)
# 获取非分片连接
@redis_connection('unique')
def get_expected(conn, key, today):
if key in DAILY_EXPECTED:
return EXPECTED[key]
exkey = key + ':expected'
expected = conn.get(exkey)
if not expected:
yesterday = (today - timedelta(days=1)).isoformat()
expected = conn.get('unique:%s'%yesterday)
expected = int(expected or DAILY_EXPECTED)
expected = 2**int(math.ceil(math.log(expected*1.5, 2)))
if not conn.setnx(exkey, expected):
expected = conn.get(exkey)
EXPECTED[key] = int(expected)
# 返回非分片连接,使得count_visit()在有需要时可以对唯一计数器操作
return conn, EXPECTED[key] Redis的Lua脚本编程
将Lua脚本载入Redis
SCRIPT LOAD: 载入Lua脚本,返回一个SHA1校验和
EVALSHA: 调用SHA校验和对应的脚本
def script_load(script):
sha = [None]
def call(conn, keys=[], args=[], force_eval=False):
if not force_eval:
if not sha[0]:
sha[0] = conn.execute_command(
"SCRIPT", "LOAD", script, parse="LOAD"
)
try:
return conn.execute_command(
"EVALSHA", sha[0], len(keys), *(keys+args)
)
except redis.exceptions.ResponseError as msg:
if not msg.args[0].starswith("NOSCRIPT"):
raise
return conn.execute_command(
"EVAL", script, len(keys), *(keys+args)
)
return call上面是一个加载Lua脚本的函数,这个脚本允许我们使用任何指定的连接而无需显示创建新的脚本对象。在调用该函数第一次执行命令时,会调用SCRIPT LOAD,之后会调用EVALSHA。
由于脚本在返回各种不同类型的数据时可能会产生含糊不清的结果,所以应该尽量显示的返回字符串,然后手动进行分析操作。
创建新的状态信息
Lua脚本跟单个Redis命令一样,都是单个原子操作。因为Redis一次只会执行一个命令,所以EVAL,EVALSHA这两个命令也会被当作单个命令来处理。
这有效的帮助我们消除了竞态条件,不过这就导致已经对结构进行了修改的Lua脚本无法被中断。
对于不执行写命令的脚本来说,在脚本允许事件超过lua-time-limit指定的时间之后,就可以执行SCRIPT KILL命令杀死正在运行的脚本。
但如果脚本已经对存储的数据进行了写入,杀死脚本就会带来数据不一致的问题,这时就只能直接用SHUTDOWN NOSAVE杀死服务器。
Lua脚本一个最显著的优势就是它减少了与服务器的通讯次数,这不仅减少了多次通信的时间开销,还避免了 WATCH/MULTI/EXEC 事务冲突。
在开始Lua脚本演示之前,先介绍一下Redis使用Lua脚本的基本格式EVAL script numkeys key [key ...] arg [arg ...]
在宿主语言的Lua脚本代码中key和arg分别用KEYS和ARGV表示,需要注意的是,Lua中数组的下标从1开始。
def create_status(conn, uid, message, **data):
args = [
'message', message,
'posted', time.time(),
'uid', uid,
]
for key, value in data.iteritems():
args.append(key)
args.append(value)
return create_status_lua(
conn, ['user:%s'%uid, 'status:id:'], args
)
create_status_lua = script_load('''
local login = redis.call('hget', KEYS[1], 'login')
if not login then
return false
end
local id = redis.call('incr', KEYS[2])
local key = string.format('status:%s', id)
redis.call('hmset', key,
'login', login,
'id', id,
unpack(ARGV))
redis.call('hincrby', KEYS[1], 'posts', 1)
return id
)
''')以上就是用Lua脚本执行创建状态信息命令的表示,我们主要将它拆分成两部分,第一部分负责组装Lua脚本需要的参数,第二部分是Lua脚本本身。
重写锁实现
Lua实现脚本的原因
- 在EVAL命令或EVALSHA命令执行Lua脚本时,跟在脚本或SHA1校验和之后的第一组参数就是Lua脚本需要读取或者写入的键。这样做的主要目的是让集群可以拒绝那些尝试在指定分片上,对不可用的键进行读取或写入的脚本。如果事先不知道哪些键会被读取和写入,就应该使用WATCH/MULTI/EXEC
- 在处理Redis存储的数据时,程序可能会需要一些数据,而这些数据无法在最开始的调用中获取。如果在在读取时不进行一定的限制,可能会导致服务器对数据库进行许多多余的访问,造成性能下降,甚至新数据被旧数据覆盖。
def acquire_lock_with_timeout(conn, lockname, acquire_timeout=10, lock_timeout=10):
identifier = str(uuid.uuid4())
lockname = 'lock:' + lockname
lock_timeout = int(math.ceil(lock_timeout))
acquired = False
end = time.time() + acquire_timeout
while time.time() < end and not acquired:
# 执行实际的锁获取操作,确保Lua调用已经执行成功
acquired = acquire_lock_with_timeout_lua(
conn, [lockname], [lock_timeout, identifier]
) == 'OK'
time.sleep(.001 * (not acquired))
return acquired and identifier
# 检测锁是否存在,然后用给定的ttl和标识符设置键
acquire_lock_with_timeout_lua = script_load('''
if redis.call('exists', KEYS[1] == 0) then
return redis.call('setex', KEYS[1], unpack(ARGV))
end
''')Lua实现计数信号量
由于Lua版本的信号量获取操作都是在Redis内部完成,也就是说消除了系统时间不同的不公平,因为请求到来的时间统一按照Redis的内部时间计算,因此不再需要计数器以及信号量拥有者的集合。
def acquire_semaphore(conn, semname, limit, timeout=10):
now = time.time()
return acquire_semaphore_lua(conn, [semname],
[now - timeout, limit, now, str(uuid.uuid4())])
acquire_semaphore_lua = script_load('''
redis.call('zremrangebyscore', KEYS[1], '-inf', ARGV[1])
if redis.call('zcard', KEYS[1]) < tonumber(ARGV[2]) then
redis.call('zadd', KEYS[1], ARGV[3], ARGV[4])
return ARGV[4]
end
''')
def refresh_semaphore(conn, semname, identifier):
return refresh_semaphore_lua(conn, [semname],
[identifier, time.time()]) != None
refresh_semaphore_lua = script_load('''
if redis.call('zscore', KEYS[1], ARGV[1]) then
return redis.call('zadd', KEYS[1], ARGV[2], ARGV[1]) or true
end
''')移除WATCH/MULTI/EXEC
由于WATCH等命令使用的是乐观锁机制,因此在并发量很高的情况下,会导致错误出现的次数越来越频繁,产生大量重试。并且对这些异常的处理也会导致代码变得非常臃肿,下面将使用Lua脚本优化掉这些命令。
def autocomplete_on_prefix(conn, guild, prefix):
start, end = auto_complete.find_prefix_range(prefix)
identifier = str(uuid.uuid4())
items = autocomplete_on_prefix_lua(conn,
['members:' + guild], [start+identifier, end+identifier]
)
return [item for item in items if '{' not in item]
autocomplete_on_prefix_lua = script_load('''
redis.call('zadd', KEYS[1], 0, ARGV[1], 0, ARGV[2])
local sindex = redis.call('zrank', KEYS[1], ARGV[1])
local eindex = redis.call('zrank', KEYS[1], ARGV[2])
eindex = math.min(sindex + 9, eindex - 2)
redis.call('zrem', KEYS[1], unpack(ARGV))
return redis.call('zrange', KEYS[1], sindex, eindex)
''')使用Lua脚本的程序减少了通信往返带来的额外开销,并且消除了事务竞争带来的WATCH错误。
使用Lua对列表进行分片
本节将创建一种分片列表表示,并使用它去降低长度较大的列表的内存占用。这个分片列表支持对列表两端进行推入操作,以及阻塞和非阻塞的弹出操作。
为了能够对分片列表的两端执行推入和弹出操作,程序在构建分片列表时除了需要存储组成列表的各个分片之外,还需要记录列表第一个分片的ID以及最后一个分片的ID。这里按照<listname>:first和<listname>:last的格式将内容存储到Redis字符串里。
除此之外,组成分片的每一个分片都会被命名为<listname>:<shardid>并按顺序进行分配。
将元素推入分片列表
在将元素推入分片列表之前,程序需要将数据拆分成块以便进行发送。因为在程序向分片列表发送数据的时候,虽然可以直到列表的总容量,但并不清楚是否有客户端正在对列表进行阻塞弹出操作,因此用户在推入大量元素的时候,程序可能需要进行多次数据发送操作。
def shard_push_helper(conn, key, *items, **kwargs):
items = list(items)
total = 0
while items:
pushed = sharded_push_lua(conn,
[key + ':', key + ':first', key + ':last'],
[kwargs['cmd']] + items[:64])
total += pushed
del items[:pushed]
return total
def sharded_lpush(conn, key, *items):
return shard_push_helper(conn, key, *items, cmd='lpush')
def sharded_rpush(conn, key, *items):
return shard_push_helper(conn, key, *items, cmd='rpush')
sharded_push_lua = script_load('''
local max = tonumber(redis.call('config', 'get', 'list-max-ziplist-entries')[2])
if #ARGV < 2 or max < 2 then return 0 end
local skey = ARGV[1] == 'lpush' and KEYS[2] or KEYS[3]
local shard = redis.call('get', skey) or '0'
while 1 do
local current = tonumber(redis.call('llen', KEYS[1]..shard))
local topush = math.min(#ARGV - 1, max - current - 1)
if topush > 0 then
redis.call(ARGV[1], KEYS[1]..shard, unpack(ARGV, 2, topush - 1))
return topush
end
shard = redis.call(ARGV[1] == 'lpush' and 'decr' or 'incr', skey)
end
''')以上就是将元素推入列表的实现,下面简单讲解一下Lua脚本所做的操作:
- 首先检查每个列表分片的最大长度,如果没有元素需要推入,或压缩列表的最大长度太小,拒绝推入。
- 接下来根据要执行的命令获取分片列表的一端
- 在循环中先获取当前分片剩余的大小,在允许的情况下尽可能多的推入元素。此外在列表里保留一个节点的空间用来应对可能的阻塞弹出操作。
- 如果分片已经装满,修改该分片的首个/末尾分片的编号,将数据推入新的分片中。
限制:由于这个分片列表的实现无法预知元素会被推入哪一个分片里,因此无法被应用到多台服务器。
从分片中弹出元素
def sharded_lpop(conn, key):
return sharded_list_pop_lua(
conn, [key+':', key+':first', key+':last'], ['lpop'])
def sharded_rpop(conn, key):
return sharded_list_pop_lua(
conn, [key+':', key+':first', key+':last'], ['rpop']
)
sharded_list_pop_lua = script_load('''
local skey = ARGV[1] == 'lpop' and KEYS[2] or KEYS[3]
local okey = ARGV[1] ~= 'lpop' and KEYS[2] or KEYS[3]
local shard = redis.call('get', skey) or '0'
local ret = redis.call(ARGV[1], KEYS[1]..shard)
if not ret or redis.call('llen', KEYS[1]..shard) == '0' then
local oshard = redis.call('get', okey) or '0'
if shard == oshard then
return ret
end
local cmd = ARGV[1] == 'lpop' and 'incr' or 'decr'
shard = redis.call(cmd, skey)
if not ret then
ret = redis.call(ARGV[1], KEYS[1]..shard)
end
end
return ret
''')从分片中弹出元素的操作非常简单。程序需要找到位于列表一端的分片,然后在分片非空的情况下,从分片中弹出一个元素。如果列表在执行弹出操作之后不再包含任何元素,就对记录这列表端分片信息的字符串键进行修改。完成修改之后,如果当前列表中还有元素,就尝试从新的分片中弹出元素。
对分片列表执行阻塞弹出操作
因为Lua脚本和WATCH/MULTI/EXEC事务目前提供的语义和命令在某些情况下还是可能会产生不正确的数据,所以在不需要实际地阻塞客户端并且等待请求的情况下,程序应该尽可能地使用分片列表的非阻塞操作。
要想实现阻塞弹出需要使用到一些特殊操作。首先,程序会在一个给定的时限里面,尝试通过执行非阻塞弹出操作来获得元素。如果没有成功获得,那将在循环中执行几个指定的步骤直到获取到元素或超时。
在这一系列操作中,首先要执行的就是非阻塞弹出命令。如果未能弹出元素,就会获取第一个和最后一个分片ID,然后对指定端点尝试弹出。
由于通信往返的延迟,在程序获取分片列表端点之后,直到开始尝试弹出这段时间里,列表的端点可能已经发生了变化。为了解决这个问题,程序在执行阻塞弹出操作之前,会先发送一个被流水线包裹的EVAL脚本调用。这个脚本会检查程序是否在尝试从正确的列表里弹出元素,如果是的话不做任何操作,之后的阻塞弹出也会正常进行。但如果弹出操作针对的是错误的列表,就需要向那个列表推入一个额外的伪元素,这个元素会在之后被弹出操作弹出,告诉客户端分片端点发生变化。
尽管如此,仍存在一个潜在的竞态条件:如果一个客户端在Lua脚本执行之后,弹出操作之前向服务器执行了推入或弹出操作,就会导致程序得到不正确的数据。
DUMMY = str(uuid.uuid4())
def sharded_bpop_helper(conn, key, timeout, pop, bpop, endp, push):
pipe = conn.pipeline(False)
timeout = max(timeout, 0) or 2**64
end = time.time() + timeout
while time.time() < end:
result = pop(conn, key)
if result not in (None, DUMMY):
return result
shard = conn.get(key + endp) or '0'
sharded_bpop_helper_lua(pipe, [key + ':', key + endp],
[shard, push, DUMMY], force_eval=True)
getattr(pipe, bpop)(key + ':' + shard, 1)
result = (pipe.execute()[-1] or [None])[-1]
if result not in (None, DUMMY):
return result
def sharded_blpop(conn, key, timeout=0):
return sharded_bpop_helper(conn, key, timeout, sharded_lpop, 'blpop', ':first', 'lpush')
def sharded_brpop(conn, key, timeout=0):
return sharded_bpop_helper(conn, key, timeout, sharded_rpop, 'brpop', ':last', 'rpush')
sharded_bpop_helper_lua = script_load('''
local shard = redis.call('get', KEYS[2]) or '0'
if shard ~= ARGV[1] then
redis.call(ARGV[2], KEYS[1]..ARGV[1], ARGV[3])
end
''')缓存
缓存雪崩
缓存雪崩是指,大量的key过期或Redis宕机导致大量请求到达数据库,使得数据库压力骤增。严重时可能会造成数据库宕机,甚至引发一系列连锁反应。
解决措施
大量key过期
- 均匀设置过期时间
- 互斥锁
业务线程处理用户请求时,如果发现数据不在缓存中,就加一个互斥锁,保证同一时间只有一个请求在构建缓存。当查询完毕时,将查询结果插入到Redis,其他请求就可以继续从缓存中获取数据。- 双key策略
互斥锁策略的缺点在于,如果构建缓存的线程长时间不释放锁,就会导致其余线程都被阻塞住。而双key策略则很好的解决了这个问题,对缓存数据可以使用两个key,一个主key设置过期时间,一个从key不设置过期时间。当线程发现主key过期了,就去从key获取数据。
这样的好处在于,即使缓存过期,服务端也可以做出快速响应。当主key过期时通知后台进程进行更新,不会阻塞其他请求。 - 后台更新缓存
缓存不再设置过期时间,由后台线程定时更新缓存。不过这么做的缺陷在于,Redis可能会因为系统资源紧张而淘汰一些key,此时对于客户端来说这些数据就好像消失了一样。
这种问题的解决方案是,当业务线程发现缓存失效后,就发送通知给后台进程,让他更新对应的key的缓存。
- 双key策略
Redis宕机
- 构建高可用Redis集群
- 服务熔断或请求限流
缓存击穿
缓存击穿指的是热点数据的缓存过期,导致大量请求到达数据库。
处理方案和缓存雪崩类似,可以使用互斥锁策略或后台更新缓存策略
缓存穿透
缓存穿透指的是,某个请求的目标既不存在于缓存中也不存在于数据库中,这就导致无法构建缓存。当有大量这种请求到来时,就会给数据库造成巨大压力。
解决方案
非法请求的限制
入参校验,若判断出是恶意请求直接返回错误缓存空值或默认值
使用布隆过滤器
在写入数据库时,使用布隆过滤器进行标记,当请求到来时通过布隆过滤器判断数据是否存在于数据库中,避免恶意请求到达数据库。
布隆过滤器
布隆过滤器包含两个部分:初始值都为0的位图数组,N个哈希函数。当要进行存储操作时,通过N个哈希函数计算出N个哈希值,并将这N个哈希值于位图数组长度取模,将位图对应位置置为1。
当查询数据时,计算N个哈希值,查看对应位是否都为1,成立则代表存在。
不过由于可能的哈希冲突,过滤器判断存在不代表一定存在,但判断不存在就代表一定不存在。
数据库和缓存一致性
要保证数据库和缓存的一致性,最容易想到的方式就是更新数据库的同时更新缓存。但这种方式会有很严重的并发问题,如果线程A先更新了数据库,然后线程B更新了数据库与缓存,最后线程A更新了缓存。这就会导致数据库与缓存不一致。
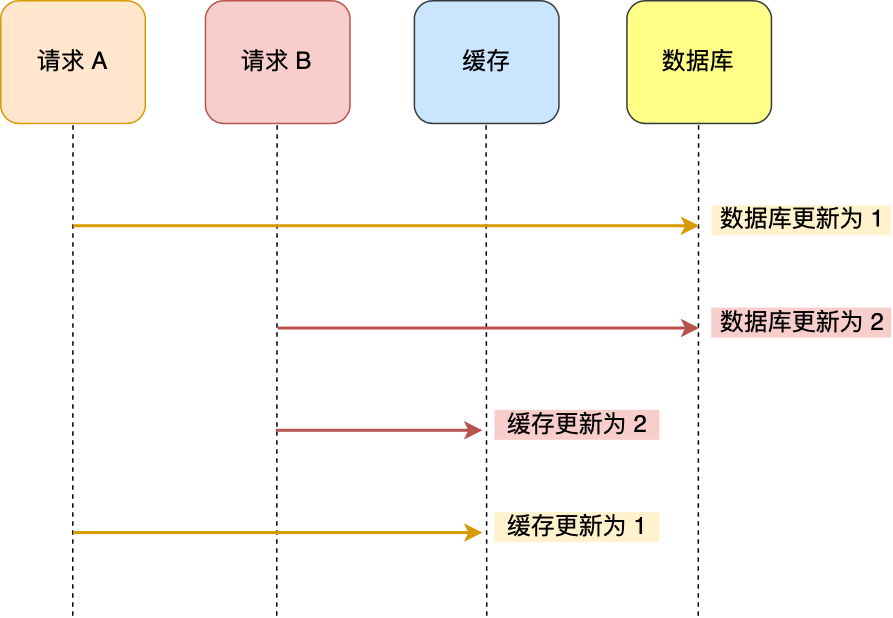
先更新缓存再更新数据库也会有一样的问题
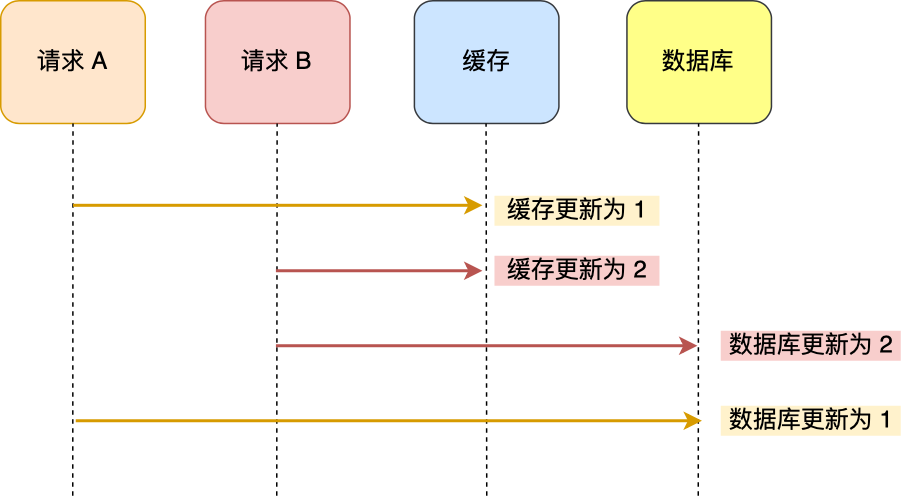
为了解决同时更新带来的并发问题,我们需要采取Cache-Aside策略
也就是当数据库更新时,将缓存删除,读取时再重新构建缓存。
不过这种策略也同样有点问题,如果先删除缓存再更新数据库,仍可能出现不一致。
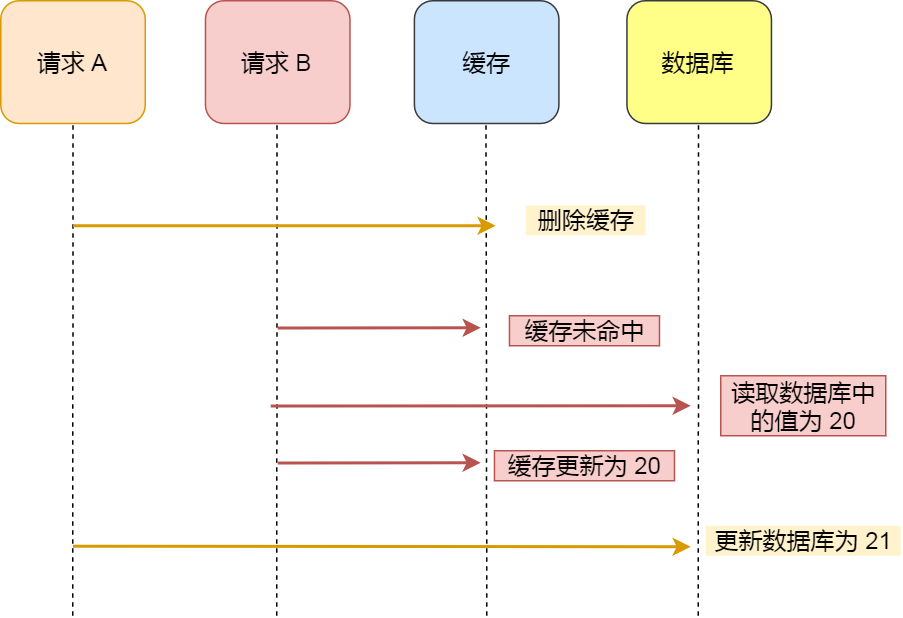
先更新数据库再删除缓存也有可能出现不一致,不过这种情况出现的概率非常低。因为缓存的操作远比数据库快,后来的请求不太可能在先到的更新请求的数据库更新与缓存清除操作间完成所有任务。
综上所述,最好的方式是先更新数据库再删除缓存。而为了万无一失,最好还是给缓存key设置一个过期时间。
不过即使采用了上述所有策略,仍有可能会出现bug,一旦缓存删除失败就会导致旧数据暴露给用户。
究其原因是我们保证两个操作的原子性。这有以下两种解决方案:
重试机制
将缓存删除操作存储到消息队列中,由消费者读取数据并重试删除操作订阅MySQL binlog
通过类似Canal的中间件订阅MySQL的binlog,获取具体需要的操作,然后再执行缓存删除
- 标题: Redis入门
- 作者: Zephyr
- 创建于 : 2023-01-25 11:01:27
- 更新于 : 2023-03-11 14:50:03
- 链接: https://faustpromaxpx.github.io/2023/01/25/redis/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。