Remake | 数据库
菜狗的Remake之路 – 数据库篇
Database
SQL
Grammar
sql描述的是我需要什么,而非怎么做。底层交给DBMS实现。
limit
limit [Integer]
查找表中前Integer条记录。通常与orderby一同使用。
group by
将表切分成多个组,并以表为单位进行相关操作。
group by不允许直接查询非group by参数的字段。
re: group by会将许多记录作为整体操作,但非group by参数字段在分类后其数量在同一组中也势必>=1 无法成为一个整体被反映到表中,因此不被允许。
所有的聚合函数都需要针对一个组来使用,如果不显式指明,则整张表作为一个组。
Having对查询出的组根据给定条件进行过滤。
like
WHERE xxx LIKE 'B_%'
-- _ means any character. % means any number of that character
-- Regular expression
-- ~ means match
WHERE xxx ~ 'B.*'
集合运算
UNION: 取并集
INTERSECT: 取交集
EXCEPT: 取差集
加上ALL代表显示重复值。
view
create view view_name
as select_statement临时视图
SELECT bname, scount
FROM Boats2 B,
(
SELECT B.bid, COUNT(*)
FROM R.bid = B.bid AND B.color = 'red'
GROUP BY b.bid
) AS Reds(bid, scount)
WHERE Reds.bid = B.bid AND scount < 10
WITH tablename(columns...) AS (select_statement)Concept
SQL执行流程
SELECT DISTINCT target-list
FROM single table
WHERE qualification
GROUP BY grouping list
HAVING group-qualification- FROM 确认要查询的表
- WHERE 筛选满足条件的记录
- SELECT 保留所需要(出现在SELECT/GROUP BY/ HAVING)的字段
- GROUP BY 形成需要的组
- HAVING 筛选满足条件的组
- DISTINCT 去除冗余的记录
Division
查找拥有所有船只的船员 ==> 查找没有哪艘船不持有的船员
select s.sname
from Sailors s
where not exists (
select B.bid
from Boats b
where not exists (
select R.id
where R.bid = B.bid
And R.sid = S.sid
)
);NULL
NULL代表不确定
所有与NULL直接进行判定的操作都被判为False
聚合函数会忽略其所有操作的字段中的NULL值
Hardware
Disk
访问的方式不是通过指针解除引用,而是借助API
READ:将一页数据从磁盘移到内存中,然后通过内存的地址对磁盘进行访问
WRITE:将一页数据从内存写入磁盘
注意API调用的速度都非常慢,需要良好的规划。
访问一个页的时间消耗
查找:磁盘臂将磁头定位到目标位置
旋转延迟:等待目标数据块旋转到磁头下
传输时间:将数据从磁盘读取到内存
主要的IO时间消耗在查找和旋转延迟上
预测行为
缓存访问次数多的数据块
提前将很有可能被访问的数据提取到内存中
若要写入的是连续的数据块,则可以先进行缓存,最后一并写入。
磁盘中数据块的组织
Next block concept:
- 在同一磁道上连续的数据块
- 在同一磁盘上的数据块
- 在相邻磁盘上的数据块
因此可以将文件的数据块在磁盘上连续存储,来介绍查询和旋转延迟
对于顺序的扫描,就可以做到提前提取,一次读取大量连续的数据块(一次性将文件的大部分提取到内存中)
Files
表会被存储为逻辑文件,由数据块构成,每个数据块中都存储一系列记录
DB File Structures
Unordered Heap Files
记录在页中随意存放,适用于经常查询所有记录的情况
Clustered Heap Files
记录和页被分组存放
Sorted Files
记录和页按某一顺序存放
Index Files
可能会包含指向其他文件中记录的索引
Page
Header会包含:
- 记录数量
- 空余的空间
- 可能会有指向下一个元素的指针
- 可能会有Bitmaps
布局
方向:
记录数量(定长还是变长)
是否打包
定长:
打包
让记录稠密分布,类似链表的形式。
Record id = (pageId, record number in page)
添加元素十分容易,但删除需要重组数据,让后面的数据填补被删数据的空白。
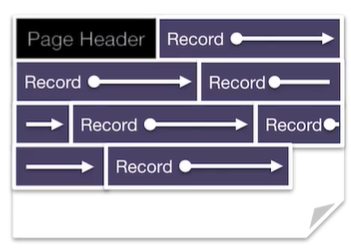
不打包
在头部添加bitmaps,标记每个存储单元的存储情况
在插入时只要寻找首个还没被标记的存储单元即可
删除时只需要清除bitmaps中对应的位即可
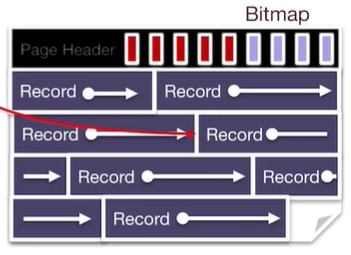
变长:
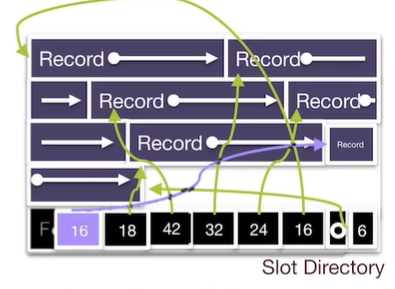
在page的底部维护一个slot directory,第一个元素(从右往左)为记录的个数,第二个为指向首个空地址的指针,其余位置放置各个记录的id。
插入元素时,只需要直接插入第二个指针指向的存储单元,并用一个闲置槽记录新纪录的id即可
删除元素时,回收对应的存储单元,并清除对应id所在的槽。
删除会导致page中出现不连续的空闲空间,此时可以对其进行再分配,也可以等剩余连续空间用完后再清理。
而当page大小需要变化时,例如page需要扩容,则直接在slot directory的最后添加记录id即可(从右往左看)
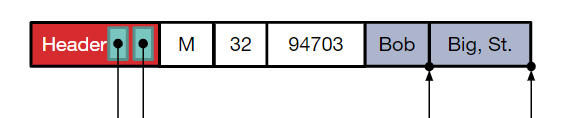
Record
关系模型
每条记录都有一些固定的类型
不将类型信息存储在记录中而是放在系统目录中,以此节省空间,
定长
在一个文件中,所有记录中字段的类型都是一致的
在内存和磁盘中字节的表现形式一致。
变长
将变长的字段放在尾部,添加一个记录头,其中存储指向变长字段的指针以及长度
Index
索引是一种数据结构,利用search key实现对data entry的快速查找和修改
查找操作需要支持许多类型的操作,例如比较时需要考虑一维还是二维比较
search key可以是表字段的任意子集,并且不一定要是unique键,也可以是某具有唯一性的复合属性
data entry:存储在索引中的条目
ISAM
最简单的做法:对存储键值的文件使用二分查找。但因为有跨页中断,因此效率一般
改进:再多加一层连接不同的page,将其作为查找树的根节点。节点本身的键值起到标识左右子树范围的作用。
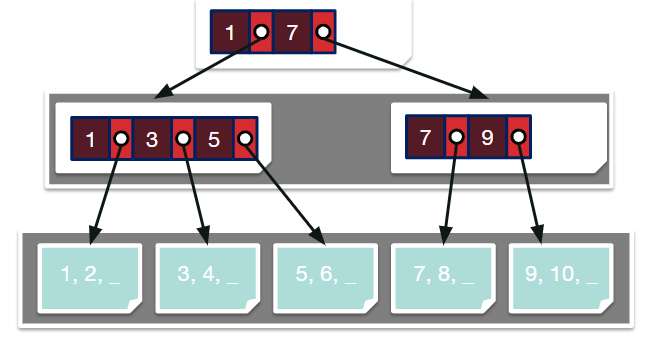
压缩:每个内部节点的最左边的值可以被省略。
插入:在指定位置插入对应节点,可能需要重新排序。如果插入后会超出原先能容纳的数据量,则会再开辟一块Overflow pages存储,被逻辑连接到最后一块页数据之后。随着超出数据量的增多,查找速度会逐步退化成线性。
B+ Tree
结构与ISAM类似, 节点存储<Key, Page Ptr>
但B+树可以实现动态索引,保持树永远是平衡的,并且支持更高效的插入和删除,因为增长都体现在根节点而非叶子节点。
约束条件:
- 每一个内部结点至少被填满一半,d <= #entry <= 2d
- d称为B树的阶数,结点最大扇出数为2d+1
B+树的叶子结点之间必须做逻辑连接,因为他不像ISAM一样在物理层面就连在一起,但这也方便它进行动态分配。
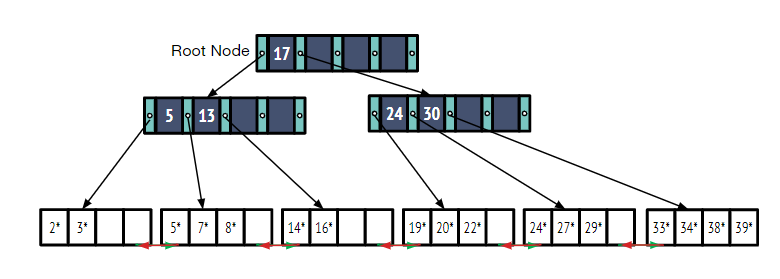
插入操作:
查找到新数据应在的叶子结点
若该结点未满:直接将其存入,并重新排序
若该结点已满:分裂当前结点,建立一个新的结点,将现有的2d+1个数据中较小的d个拷贝进一个结点1,另一部分拷贝进另一个结点2。然后将结点2中最小的数据拷贝一份传入父节点中。若父节点已满重复上述步骤。
如果要向新的索引结点传递数据,则直接推入,而非拷贝。
re:对于B+树来说,所有的数据都存在叶子结点,因此必须在叶子结点保留相关数据,而其对应的值则可以传到索引结点起到划分域的作用。
大规模插入操作:
将要插入的数据按照键先进行排序,然后直接向叶子结点插入数据,超出可容纳个数时就进行分裂,确保每一个叶子结点中的数据量都达到插入因子。这样和反复的插入相比节省了大量IO时间,已经完成装载的部分不会被算法考虑,节省时间。
索引结构需要考虑的问题
- 支持的查询
- Search key的选择
- 数据的存储方式
- 变长键的处理
- 性能消耗
Search Key and Ordering
在一个有序的索引中,它的键都会按照字典序排列
字典序:先比较search key中的第一个字段,若相等,继续比较第二个字段,以此类推。
一个复合查询键的格式:整个查询由m个等值比较与一个大小比较(必须放在最后)构成。哦
Data Entry Storage
数据在索引中的存储方式:
- 值
- 单一引用
- 引用链表(当数据量很大时,单一引用的存储方式会分裂出大量的索引记录)
如果存储引用,则必须能支持多索引查询,否则就需要为每个索引都建立一个索引文件,导致数据冗余,加大修改数据的难度。
Clustered vs. Unclustered Index
聚合索引会根据search key确保索引大致有序(并不要求绝对顺序)
因此聚合索引往往能提供比较好的查询性能。同时顺序的磁盘访问也有助于进行类似prefetching之类的优化工作,并且也方便进行压缩操作。
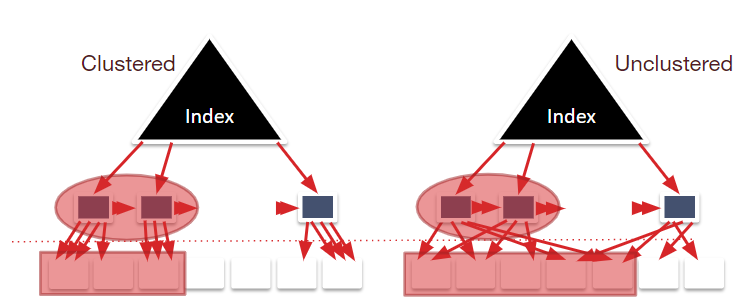
对于聚合索引,它在查询时要涉及的页明显少于非聚合索引。
但聚合索引的维护成本相对较高,并且由于其在初始插入时会预留1/3空间给之后的插入操作,会带来一定的空间浪费。
Variable Length Keys & Records
当字段为变长时,顺序就失去了意义(难以比较),不同的结点会存储不同长度的条目。与此同时,不同索引存储的记录引用个数也会产生较大的差距,不利于高效查询。
因此针对变长的字段,我们在要求填充超过半数时,是从字节数的角度进行衡量。
键后缀压缩
提取记录中键的最小前缀放在头部,然后将剩余部分链接上去。
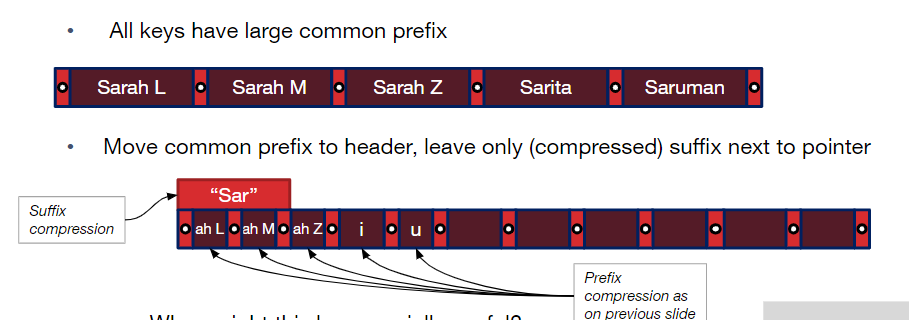
适用于复合键,且首个属性个体差异不大,之后的属性差异较大。
Buffer Management
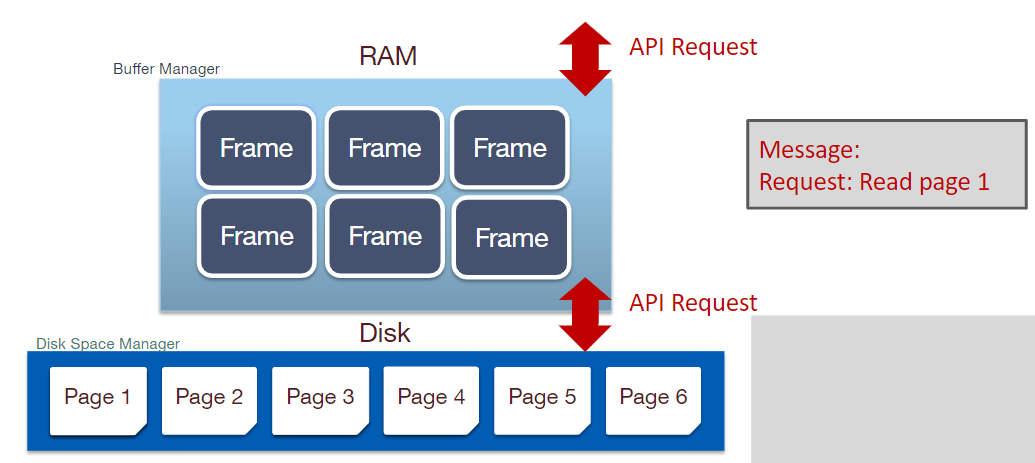
当上层向缓存发起请求时,缓存会先在内部查找有没有需要的数据页,如果有,直接返回,如果没有,从磁盘读取到缓存,然后返回。
脏页:在缓存中有数据被修改,但还没有刷入内存的数据页
处理方式:用一个dirty bit标识当前页是否是脏页。
| FrameId | PageId | Dirty? | Pin count |
|---|---|---|---|
| 1 | |||
| 2 | |||
| 3 |
Pin count显示当前有多少任务在使用该缓存
Replacement Policy
替换策略:
Least-recently-used(LRU), Clock
Most-recently-used(MRU)
根据访问的数据特征选择
LRU
替换原则:挑选当前不被使用的,且在近期都没有被使用的数据页替换
方法:在缓存池的结构中添加一个记录上一次使用截止期的字段
| FrameId | PageId | Dirty? | Pin count | Last used |
|---|---|---|---|---|
| 1 | ||||
| 2 | ||||
| 3 |
优势:对于部分数据需要被频繁访问的情况很友好
劣势:找到最不受待见的数据页需要线性时间(可以用堆优化到对数级)
Clock
一种类LRU策略,用一个指针依次扫描缓存池中的Frame,在结构中添加一个字段表示是否为最近访问的字段。
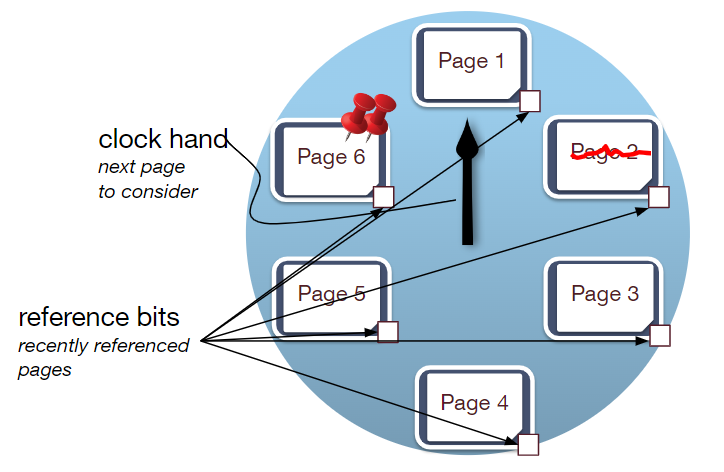
若指向的页正在被使用,直接跳过。若指向的页ref bits为1,且没有被使用,则将ref bits置为0。若某页既没有被使用,ref bits也为0,则将它替换下来。
Clock替换掉的仅仅是当前不热门的数据,而LRU会替换掉最不热门的数据,因此Clock相对来说开销会小一点。
但LRU类型的策略在面对大型数据时都存在致命缺陷:
当数据页的数量超过了缓存池的大小时,缓存命中率会直接降为0。考虑文件长度为7页,缓存池大小为6页,读取前6页时都在填充缓存池,当读取到第7页时,会将第1页踢掉。若下一步是再次读取第1页,则又需要讲第1页重新从磁盘读入缓存。LRU会将后续马上要用到的数据踢出缓存,大大降低了效率。
MRU
当MRU处理大型文件时,第一轮与LRU无异。但在处理第7页数据时,它会踢掉最近使用的,也就是第6页。之后再次读取第1页时就会命中缓存,平均每次读取缓存命中次数为B - (N-B)。因此当文件过大时,命中次数也会下降。
综上:LRU在随机读取,涉及热门程度的数据的读取上占据优势。MRU在重复读取上占据优势。DBMS会根据查询数据特征选择相对优秀的策略。
DBMS vs OS Buffer Cache
OS不会管理数据库的缓存
re:
- 不同OS支持的操作不相同,但都会支持DBMS,因此放在DBMS上具备更好的适配性
- OS只能识别物理层面上的连续的数据页,而DBMS可以根据其索引,例如B+树叶子结点的兄弟属性来识别逻辑上连续的数据页,能够更好的进行类似pre-fetching的操作。
- OS无法强制让数据刷入磁盘。
Sorting and Hashing
out-of-core algorithm
Single passing Streaming
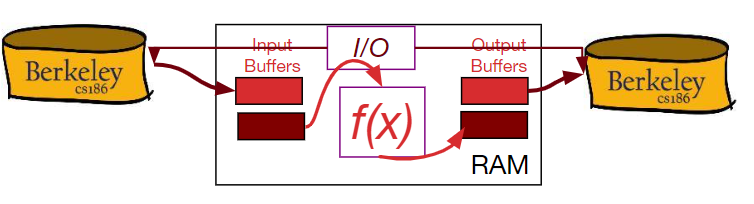
利用函数f(x)将记录映射为另一个值。
尽可能地减少RAM的使用(映射函数需要让产出的结果占用空间小于其对应的记录),降低IO使用率。
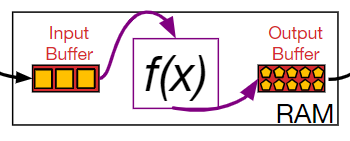
Double Buffer
主线程利用一对输入输出缓冲区进行常规的映射操作。
另加一个IO线程,向目前没有使用的输入输出缓冲区填充/释放数据。
当主线程完成操作,等待缓冲区时,直接交换缓冲区。
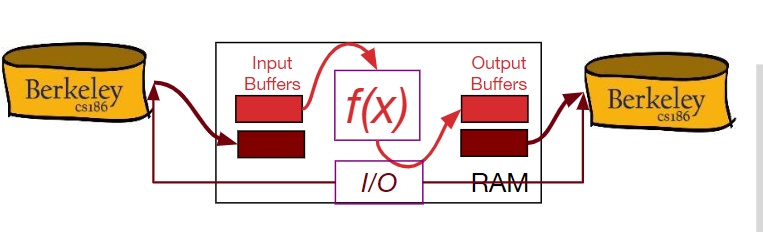
2-Way
Pass 0:
读取一个数据页,排序并写入。
只使用一个缓冲区。
重复类似步骤,将整个文件包含的数据页写入,并保证每一页有序。
Pass 1,2,3 …:
至少需要3个缓冲区(假设每个缓冲区的大小为一个数据页)
将两个输入缓冲区的数据进行归并排序传给输出缓冲区。
2-Way External sort
拥有>3个缓冲区
Pass 0:
使用B个缓冲区,每次导入B页数据,总共需要N/B(上取)个runs,每一个runs里运行一个排序进程。
Pass 1:
每个runs的数据长度为B,本轮可以进行B-1个runs的归并
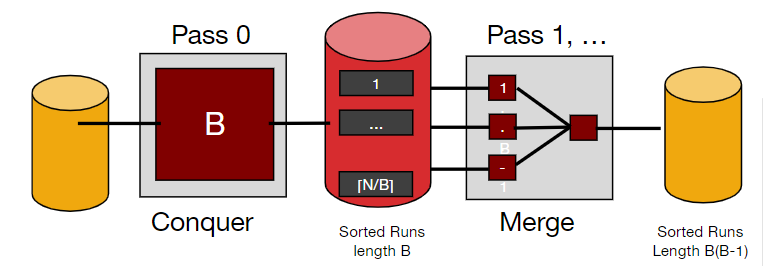
因此在Pass 1可以完成B(B-1) pages数据的排序。
Hash
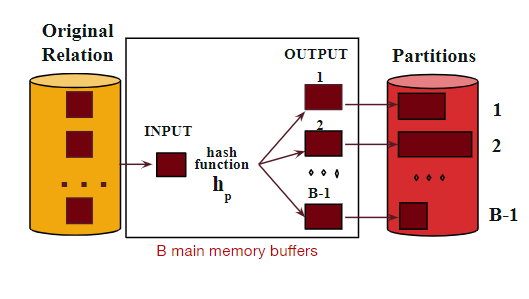
将数据分批读取到内存中,在进行hash操作。
两步骤:
Divide
使用哈希函数hp将记录流传递到指定的磁盘分区
满足匹配条件的都处在同一分区,确保具有同样特征的值不会在内存中被不同的哈希表计算(去除冗余)。

Conquer
利用哈希函数hr,将分区读取到RAM的hash表中
然后读取桶中的数据,并将它们回写到磁盘中
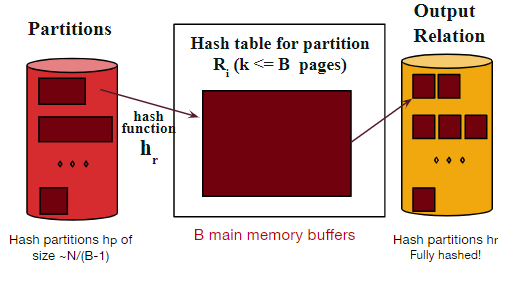
若划分之后的数据块还是很大,则进行递归划分操作,满足条件后再进行Conquer。
Iterator
关系操作符和查询规划
假设有一查询
$$
𝜋_{sname}(𝜋_{sid}(𝜋_{bid}(𝜎_{color}=’red’(Boats)) ⋈ Res) ⋈ Sailors)
$$
则其对应的数据流图为
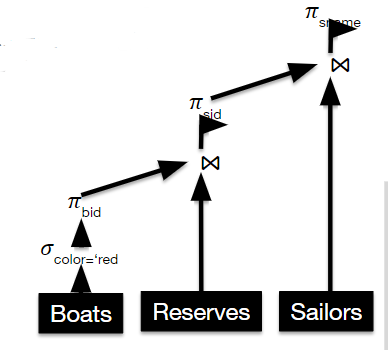
其中每一条边都代表数据的流向
结点代表关系运算符
源代表某个关系
迭代器
对于每一个关系运算符要做的操作都会有一个对应的迭代器。筛选传入数据流中符合条件的元素,再传递到下一个操作的迭代器中。
abstract class iterator {
void setup(List<Iterator> inputs);
void init(args);
tuple next();
void close();
}init和next操作可以采取流式或批量算法
流式:每次调用只有少量,有限的工作。
批量:每次执行一系列的工作,在完成之前不会产生输出。
Select
init(predicate):
child.init()
pred = predicate;
current = NULL;
next():
while (current != EOF && !pred(current))
current = child.next();
return current;
close():
child.close()
首先初始化自己的子结点,并装配断言
next():不断循环直至到达文件末尾或是当前字段满足断言条件
Heap Scan
该迭代器不可能有孩子,因为其处于最底层,负责从磁盘中读取指定关系的数据。
init(relation):
heap = open heap file for this relation;
cur_page = heap.first_page(); // first page
cur_slot = cur_page.first_slot(); // first slot on that page
next():
if (cur_page == NULL) return EOF; // End Of Fun
current = [cur_page, cur_slot]; // we will return this recordId
// advance the slot
cur_slot = cur_slot.next();
if (cur_slot == NULL) {
// advance to next page, first slot
cur_page = cur_page.next();
if (cur_page != NULL)
cur_slot = cur_page.first_slot();
}
return current;
close():
heap.close()Sort
init(keys): // all of pass 0 in init, a blocking call
child.init()
repeatedly call child.next() and generate the sorted runs on disk, until child gives EOF
// set up for pass 1, assumes enough buffers to merge
open each sorted run file and load into input buffer for pass 1
next(): // pass 1 (assumes enough buffers to merge)
output = min tuple across all buffers
if min tuple was last one in its buffer, fetch next page from that run into buffer
return output (or EOF -- “End of Fun” -- if no tuples remain)
close():
deallocate the runs files
child.close()
首先初始化所有的子节点,确保他们以及准备好了下一步操作。然后获取子节点的所有数据,并照上一章所讲的排序方法进行第0轮排序。完成后将所有的数据载入缓冲区进行归并。
Group By
init(group_keys, aggs):
child.init()
cur_group = NULL;
next():
result = NULL
do {
tup = child.next();
if (group(tup) != cur_group) { // New group!
if (cur_group != NULL) // Form a result for current group
result = [cur_group, final() of all aggs]
cur_group = group(tup);
call init() on all the aggs
}
call merge(tup) on all the aggs
} while (!result);
return result;
close():
child.close()
这种实现方式的前提是已经完成排序。初始化参数是要分组的键和聚合函数
next()操作:
不断获取下一个数据,直到遇见不同组的数据
当碰到新的某一组数据,且不是碰到的第一个组时,宣告本轮分组完成,结果包含当前组以及聚合函数的结果。若是碰到的第一个组,就获取对应分组并开始聚合函数的计算。
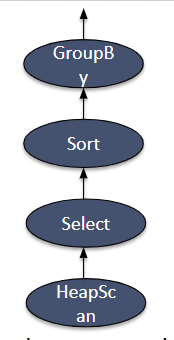
以上就是一个完整的查询流程。整个过程都不需要将输出的数据存储到磁盘。所有迭代器的操作结果都会作为上一层的参数继续参与运算,元组流只需要留存在栈中。
Join
Simple Nested-Loop Join
简单嵌套循环,每次循环从驱动表中读取一行数据,然后扫描一遍被驱动表,添加满足条件的数据。
假设驱动表R有1000张数据页,每一页有100条数据
被驱动表S有500张数据页,每一页有80条数据
则开销为:
扫描一遍驱动表要1000次IO(IO操作的单位为数据页而非记录),而对于R中每一条记录,都要扫描一遍S表,IO次数为100000 * 500
PS:若S为驱动表,开销为500 + 40000 * 1000,相对减少500次IO
Page Nested-Loop Join
和SNL相比,每次从驱动表中获取一页数据,然后从被驱动表获取一页数据。将获取的两页数据先进行一次Join操作。
此时开销降低为 1000 + 1000 * 500(R为驱动表)
演化:Chunk Nested-Loop Join
一次IO从驱动表中获取几页数据,其余操作同上。
开销可降低为 1000 + (1000 / N) * 500 N为一次性获取的页数,一般为缓冲区数-2
Index Nested-Loop Join
驱动表在拿到数据后,直接根据关联字段的索引进行查找。和上述的方法相比,该方法每从驱动表取出一条记录,都只要去查询被驱动表的索引,查询次数为索引的高度。
开销为:驱动表页数 + 驱动表记录数 * 索引树高度
Sort-Merge Join
条件:有相同字段(自然连接)或指定的判定条件
步骤:
- 将驱动表和被驱动表按照join key排序
- 归并扫描排序后的表并提取出满足条件的元组
do {
if (!mark) {
while (r < s) { advance r }
while (r > s) { advance s }
// mark start of “block” of S
mark = s
}
if (r == s) {
result = <r, s>
advance s
return result
}
else {
reset s to mark
advance r
mark = NULL
}
} while(r)开销:R和S排序的IO开销,加上归并时,读取一遍R和S的开销
Grace Hash Join
与SNL的区别仅为预处理阶段。
将R表映射到B-1个分区,每个分区的页数都<=B-2,然后将R表的各个分区都读进内存建立哈希映射,然后将S表读入并进行匹配。
以上的做法会导致磁盘扫描次数过多,无法起到减小开销的目的。
Grace Hash Join的操作:
- 将两张表按照同一个哈希函数分配到不同的分片中,得到B-1个分区,每个分区由两张表组成Ri,Sj(R和S的子表)
- 针对每一个分区,将一张表读入内存,建立哈希表,然后读取另一张表进行匹配。
如果分区后仍然无法装入内存,则递归进行进一步分区。
Parallel Query
并行架构
共享内存
共享磁盘
无共享
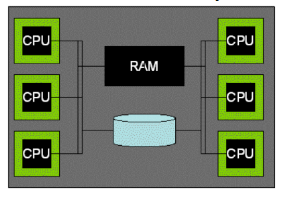
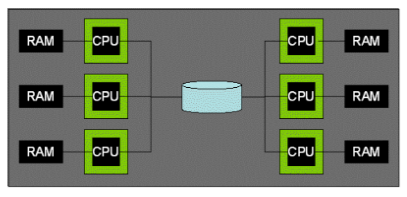
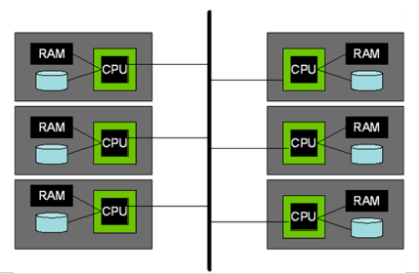
本章主要介绍无共享架构的数据库。
并行的种类
Intra-query parallel
不同的线程执行某一个单一的查询
Inter-query parallel
单个或多个线程执行许多不同的查询或事务。
数据划分
由于无共享数据库中的数据分散在不同的机器,因此良好的划分策略可以大幅提升检索效率。
Range
所有的数据根据范围分布到不同的存储器上。适合做等值连接,范围查询,分组。
Hash
通过哈希确定数据所处的分组。适合等值连接,分组。
Round-Robin
轮询策略,可以有效地分散负载。
Lookup by key
如果数据依据键分布,则可以直接检索到相关的结点。(Range, Hash)
否则就必须广播查询所有的结点。(Round Robin)
插入键值或有唯一性约束的键也类似。
Parallel Join
Parallel Grace Hash Join
- 首先将所有的数据利用哈希函数hn,分布到不同的机器上去。
- 等到第1步完成后,每台机器都在本机对得到的数据进行进一步的Hash操作。
- 每台机器完成Hash后,进行 GHJ
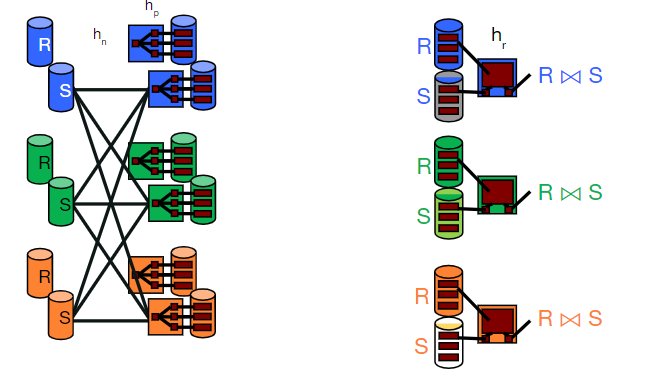
整个过程只有第一步需要机器等待数据分发完毕,其他时刻都不存在等待,因此效率会比较高。
Parallel Sort-Merge Join
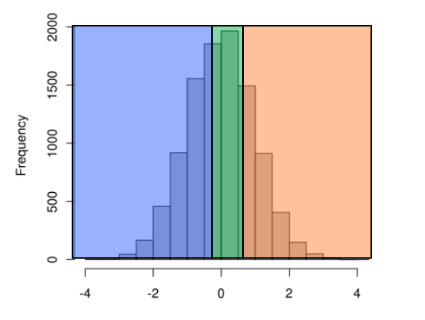
Pass 0:将数据按照范围传送到指定的机器上去。
范围选取方式:根据输入获取样本,并根据每个范围内的数据量进行分割。如下图所示,频率高的区间,范围小,确保数据在每台机器上平均分布。
Pass 1:在每台机器上进行Sort-Merge Join操作
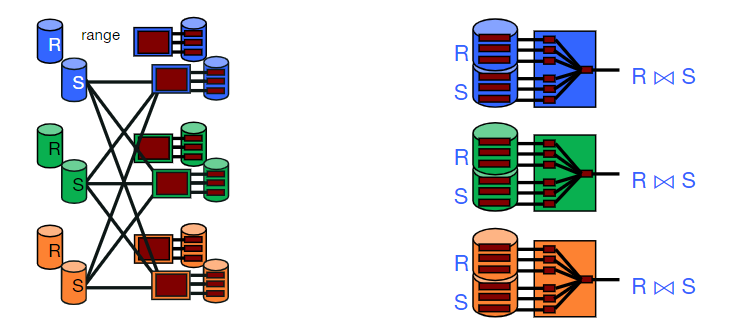
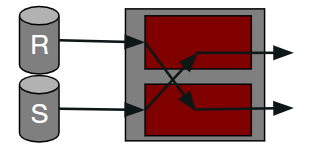
Symmetric Hash join
无论是Hash join还是Sort Merge Join都有一个等待同步的过程。但Symmetric Hash Join可以做到整个Join过程没有任何等待,且全程只需要流式传输。
这种Join方式让每台机器都为驱动表和被驱动表各维护一张哈希表,每当一个数据到来,就将其添加到对应表的哈希表中,然后让该数据去探索另一张表的哈希表,寻找可以匹配的记录并输出。
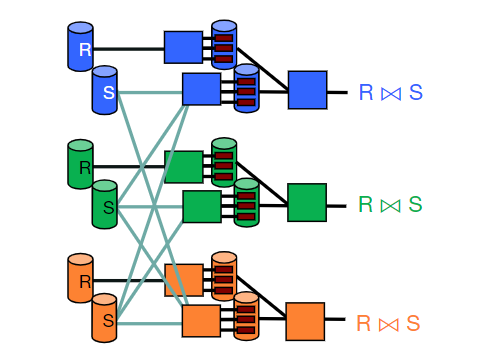
One-side shuffle Join
如果R表本身已经被合理地划分了,就只划分S表,然后在每台机器上进行join并合并结果。
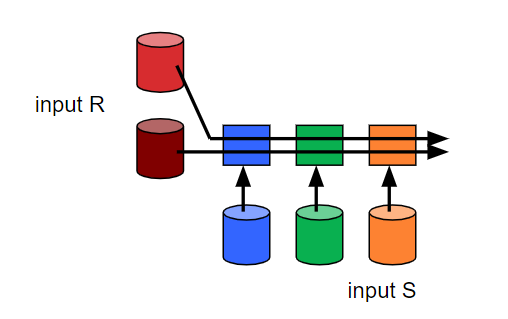
Broadcast Join
如果R表很小,那就将它传送给每一个获得S表分块的机器上
Query Optimization
结构
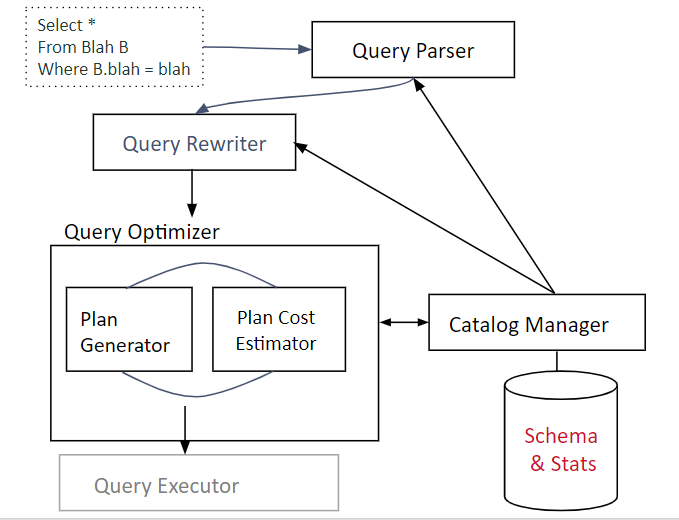
Query parser
检查SQL语句正确性,并鉴权。
生成语法树
Query rewriter
将查询转换为规范格式:
- 扁平视图
- 将子查询分解为更少的查询块
优化手段
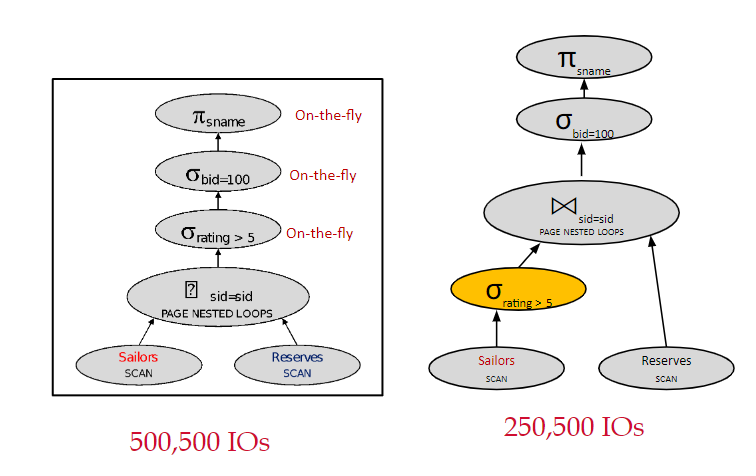
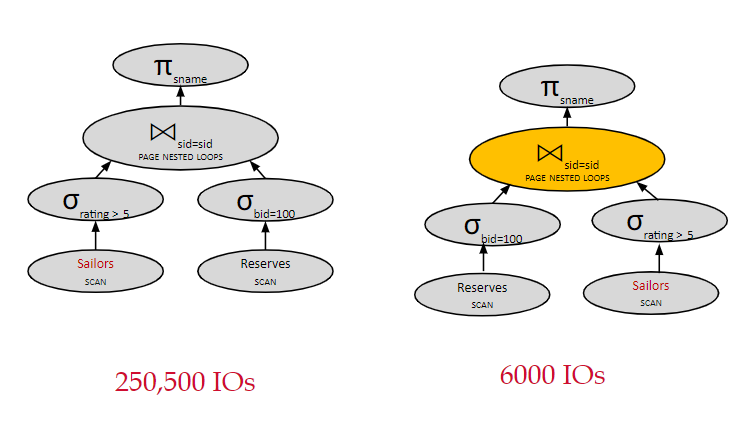
选择操作:在获得了相关的字段之后,就先对其进行选择操作。使得进入之后操作的数据量减少。
需要注意的是,如果是提前被驱动表的选择操作,则对IO不会有什么提升。在进行join操作时,每次驱动表发起探索,都要去提取整个被驱动表,不会减少被驱动表要检索的记录数。但放在驱动表前可以有效减少参与探索的记录数。
投影操作:只保留下流操作需要用到的字段。使得单个record变小,page能存下更多record。
两表连接时,选择需要发起探索的记录数少的表作为驱动表。
物化临时表到内存中:上文提到被驱动表提前进行选择操作无优化作用的原因是每次都会重新提取一整张被驱动表。但如果在做完选择操作后,将该临时表物化到内存中,就可以让驱动表与该临时表进行join,大大减少要探索的记录数。
选取更加高效的Join算法。
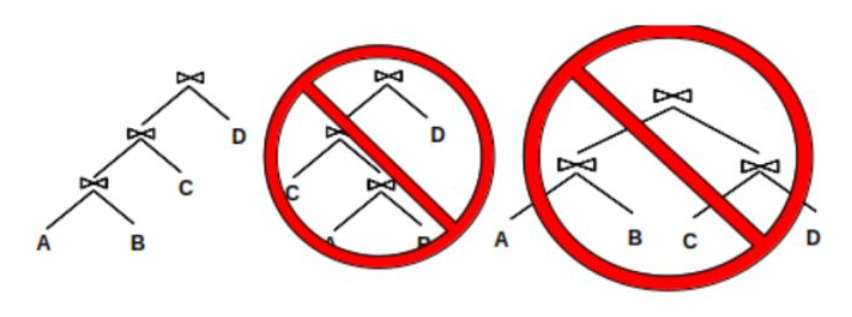
只考虑使用左深树,即每次join的结果都作为左表,新加入的表作为右表。使得join操作可以流水线式操作,中途不需要将临时表物化进内存,减少物化带来的额外io开销。

DB Design
ER Models
Data Model:描述数据定义的概念集合
Schema:基于使用数据模型,对特定一组数据集合的描述
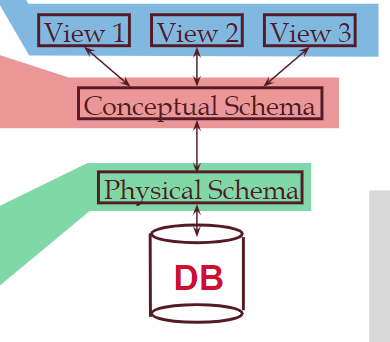
Levels of Abstraction
External schema:描述用户看到的数据
Conceptul schema:设计逻辑结构
Physical schema:描述文件和索引的使用
key constraints
键约束,持有键约束的实体类,代表它的每一个对象在对应的关系中至多参与一次,也就是说该实体类在1-many中为many的一方。
箭头代表该实体在这个关系中持有键约束。
participation constraints
参与约束,描述某一个实体在该关系中是全部参与(不可为null)还是部分参与,将连接实体与关系的线加粗代表该实体在本关系中全部参与。
弱实体
一个弱实体只能借助其依赖的强实体的主键标识。其具备如下特征:
- 对应的强实体和弱实体必须构成一对多关系。
- 弱实体必须是全部参与
- 弱实体可以包含部分键,用来进一步唯一标识该弱实体。

Aggregation
允许某一个关系成为另一个关系的参与者。
例如,下图表示员工监管部门对项目的投资。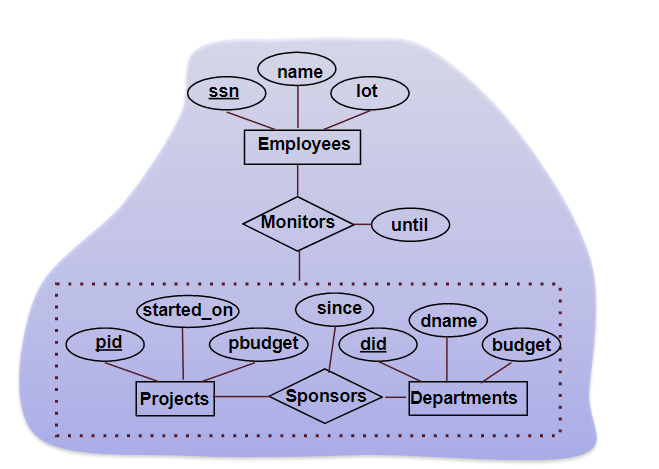
FDs and normalization
函数依赖的定义:若有X -> Y (->可以读作决定),则当X相等时,Y必然相等。
关键术语:
- 超键:一系列决定表中所有字段的字段集合。
- 候选键:决定表中所有字段的最小字段集合。
- 主键:被选取的某个候选键。
- 索引键:用于索引的某个键(与本章探讨的内容无关)
表中存在对非键属性的依赖存在的问题(数据冗余)
- 更新:每次更新必须对涉及的所有元组进行修改,否则会导致数据不一致。
- 插入:若插入时依赖的属性错误或不确定就会破坏数据一致性。
- 删除:如果删除了非键属性特定值的记录,那么我们就会失去该属性对应的指定值。例如:r=5 -> y=7,若删除r=5的所有记录,则我们会丢失r=5时y的值。
但对键的依赖不会导致数据冗余,因为键本身具备唯一性。
Decomposition
分解可能导致的问题
- 可能导致原始关系无法重建(破坏性的分解)。
- 依赖的检查可能会需要join。
- 一些查询可能会变的非常昂贵。
以上是在分解时需要考虑的问题,分解带来的好处是否能够超过上述问题带来的弊端。
Lossless Join Decomposition
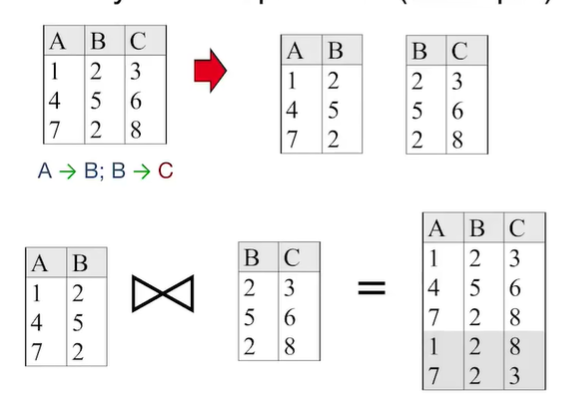
无损的分解:如果将关系R分解为X和Y,对于每一个满足函数依赖F的实例r,都要求$π_x(r) ⋈ π_y(r) = r$。
通俗来说就是要求,分解后作为拼接两个关系的字段,必须能唯一标识某一张表中其余被拆分的信息。例如,本例中将ABC -> AB和BC,就要求B能够唯一标识A或C,在本例中明显做不到。如果我们使用将其拆分成AC和BC,则可以达成这个目标,但就会导致另一个问题,A->B这个函数依赖没有被保存在任何一个拆分后的关系中,也就是每次检查该依赖都要进行join,这就引出了另一个问题:保留依赖的分解。
Dependency Preserving Decomposition
保留依赖的分解,要求分解后每一个关系中函数依赖的并集等于原先的函数依赖集合(简单理解)。这就要求每一次分解之后,每一个函数依赖涉及的字段必须存在同一张表中。
eg. BCNF的分解
对任意违反BCNF的函数依赖X->Y,都可以将其分解为R-Y和,XY,其中X可以唯一标识Y,因此一定是无损依赖。
但是未必可以做到保留函数依赖,例如R={C,S,Z}, F={CS -> Z, Z->C}(切分一个首尾相连的结构必然破坏其结构特性)。
Concurrency
事务
事务是一系列操作组成的工作单元,该工作单元内的操作是不可分割的,即要么所有操作都做,要么所有操作都不做,这就是事务。
ACID
automic:原子性,事务中的操作要么全部执行,要么都不执行
Consistency:一致性,事务应当维护数据库的完整性约束
Isolation:隔离性,并行的事务不应当相互影响
Durability:持久性,事务一旦被提交,所产生的更改是永久性的
可串行化
并行出现问题的最明显特征:针对某一数据A,事务1的读取发生在事务2的写入之前,而写入发生在之后(如果事务1仅仅做读取操作,则不会有问题)。
可串行化调度:如果一段并行调度产生的结果和串行调度产生的结果一致,则称为可串行化调度。
冲突可串行化调度:在可串行化调度的基础上,满足交换没有冲突的操作可以变成串行调度。
冲突:
- 在同一事务中的对同一数据的所有操作都相互冲突。
- 在不同事务间,对同一数据的读写,写写操作冲突。
锁
两段锁协议
共享锁:事务获取该锁后得到读取权限
互斥锁:事务获取该锁后得到读写权限
两个阶段
获取锁阶段:取得事务需要的所有锁,期间不能释放锁
释放锁阶段:释放之前获取的所有锁,期间不能获得新的锁
问题:普通的两段锁协议不能处理事务回滚导致的一致性被破坏
严格两段锁协议:只有在事务提交之后锁才被允许释放
更加严格的协议:获取的锁都为互斥锁
多粒度锁
我们可以将锁针对的对象大小称为锁的粒度,细粒度的锁可以帮助实现更加高效的并发,但相对的我们要创建大量的锁来确保对数据的精确操控,需要的空间更多。粗粒度锁虽然不能对数据进行细致的操作,但是相对来说它的数量并不需要太多,占用的空间更小。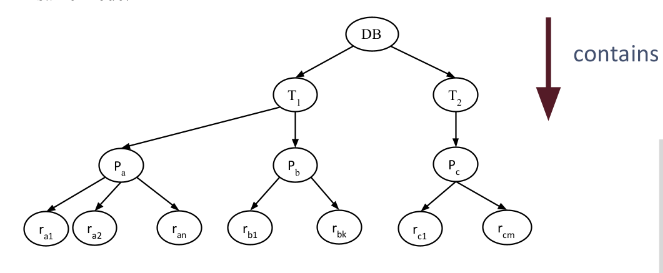
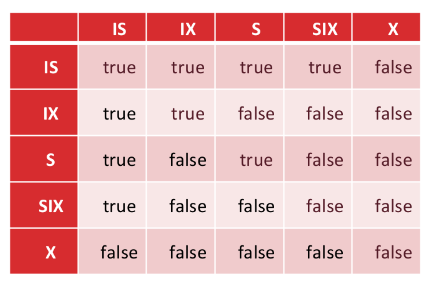
意向锁
当某个事务获取指定一个结点的锁时,它将隐式地锁定该节点的所有子节点。意向锁协议便是为了解决这个问题。
在本协议中,多了3中额外的锁:
- IS:代表有意向获取共享锁的意向锁。
- IX:代表有意向获取互斥锁的意向锁。
- SIX:同时获取共享锁和IX。这类锁主要用于更新,既要读取结点的内容,又要表现出修改的意向。
在本协议中,如果想要锁定某一个结点,则必须获取该结点所有父节点对应类型的意向锁。
恢复
数据库恢复只要为了维护原子性,持久性,以及回滚某些破坏一致性的事务。
策略
No Steal Policy:不允许缓冲池中还未提交的脏页被页面置换算法替换。可以达成原子性,但由于未提交的脏页会长久待在缓冲池中,会拖慢效率。
Force Policy:在提交事务之前,确保所有的更新都已经被刷入数据库。可以达成持久性,但会产生随机琐碎的IO,也会拖慢运行效率。
以上两者虽然很好的维护了各自对应的特性,但是对系统性能的消耗较大,并且也没有真正意义地达成原子性(批量提交的构成中可能出现崩溃),因此现在更倾向于使用下面两种策略。
No Force:和强制策略想反,它的问题是系统可能在事务提交后崩溃,导致缓存中的修改丢失。但我们也因此可以在事务提交前,减少IO开销,同时可以通过redo操作来维护数据的持久性。
Steal:这种策略会允许脏页被提前刷入磁盘,空出缓冲区。它的问题是,系统可能会在事务提交前崩溃,事务也有可能在提交前被终止。对此我们可以利用undo来维护原子性。
上面提到的redo和undo,可以通过日志来实现
日志
Write-Ahead log
数据被写入磁盘前,其对应的日志必须先被写入磁盘。
每一个日志记录都会有一个属于自己的唯一编号,在RAM中有一个顺序文件,记录log,当日志编号达到了指定的flushLSN时,就将日志记录刷入磁盘。
每一个数据页也都有一个pageLSN,指向最近的一个涉及该数据页更新的记录。
同时日志也有一个prevLSN字段,指向当前事务的上一条日志记录。因此,每个事务的所有记录操作合起来可以看作一条链表。
在内存中有两张与内存有关的表
Transaction table
XID Status LastLSN 1 R 33 2 C 42 Dirty Page
PageID recLSN 46 11 recLSN:首个更新该表的日志编号
Undo Log: 在操作任何数据之前,先将原始数据拷贝一份,系统可以在崩溃后利用它恢复宕机前的状态。
Undo Log可以保持事务的原子性和持久性,若事务提交阶段宕机,则数据库可以依据日志恢复,若在此之前宕机则数据库内仍旧为原先的数据。
缺陷:每次事务提交都需要IO操作,但如果添加缓存会破坏持久性
redo Log: 更改数据时,保留更改后的数据。
redo log让事务提交后修改的数据可以暂时缓存在内存中而非直接提交。若事务崩溃,可以根据redo log还原事务
崩溃恢复
三步骤:
- 分析:检查哪些事务在检查点前已经提交,哪些没有提交。
从检查点开始往前查看日志,对于已经有End标识的事务,将其从事务表移除。对于有Update标记且不在脏表记录中的数据页,将其添加到相应记录中。当分析结束后,事务表中剩下的都是在崩溃时仍在活跃的事务,脏表记录中都是可能没有将数据更新到磁盘中的数据页。 - Redo:重复所有的操作。但有部分情况不需要重复。1. 受影响的表不在Dirty Page Table中,这代表涉及该表的更改已经全部写入磁盘。2. 受影响的表在Dirty Page Table中,但recLSN > LSN,这说明该表的更新发生在记录点之后,需要舍弃,因此无需重做。 3. pageLSN >= LSN,理由同上一条。
- Undo:撤销所有没有成功提交的事务。对于简单事务回滚,每回滚一条就记录一条CLR日志,CLR日志的作用是防止多次回滚。同时CLR日志还有一个额外字段指向下一条回滚日志,即日志记录中的 prevLSN。
toUndo = {lastLSNs of all Xacts in the Xact Table} while !toUndo.empty(): thisLR = toUndo.find_and_remove_largest_LSN() if thisLR.type == CLR: if thisLR.undoNextLSN != NULL: toUndo.insert(thisLR.undonextLSN) else: // thisLR.undonextLSN == NULL write an End record for thisLR.xid in the log else: if thisLR.type == UPDATE: write a CLR for the undo in the log undo the update in the database if thisLR.prevLSN != NULL: toUndo.insert(thisLR.prevLSN) elif thisLR.prevLSN == NULL: write an END record for thisLR.xid
Distributed transactions
分布式事务本质上属于 share-nothing prallel
锁的分配
一种典型的设计就是:根据数据的分区分配锁。这样每一个结点(数据页/元组)可以管理它自己的lock表,对于粗粒度锁,因为它很有可能涉及跨分区锁定,因此我们专门给它分配一种home锁。
通过这种锁分配机制,可以简洁高效的管理锁,但死锁和commit/abort的问题依旧没有解决。
死锁的处理在此不多赘述,主要记录一下分布式提交的理解。
Distributed Commit:2PC
分布式系统的一大特点就是不同步,但如果我们希望提交某一个事务,那必然需要涉及的所有结点都已经准备好了提交,通俗来讲就是,想提交某个事务必须得到所有相关人士的同意。也就是类似投票的机制。
在面对信息传输延迟/失败的情况下,我们就需要2 Phase Commit来实现分布式投票。
在阶段1中,协调者会询问所有的结点是否准备好了投票/提交事务。
- 协调者询问结点是否已就绪。
- 参与者生成prepare/abort记录,并将其写入磁盘。
- 参与者返回自己是否参与投票的应答。
- 协调者生成提交记录(如果结点都同意),并写入磁盘。
在阶段2中,协调者就会根据投票结果选择对事务的操作,并将其广播。
- 协调者广播投票结果。
- 参与者生成有关结果的记录,并写入磁盘。
- 参与者返回一个ack。
- 协调者生成一个end记录,并写入磁盘,标志该事务完成操作。
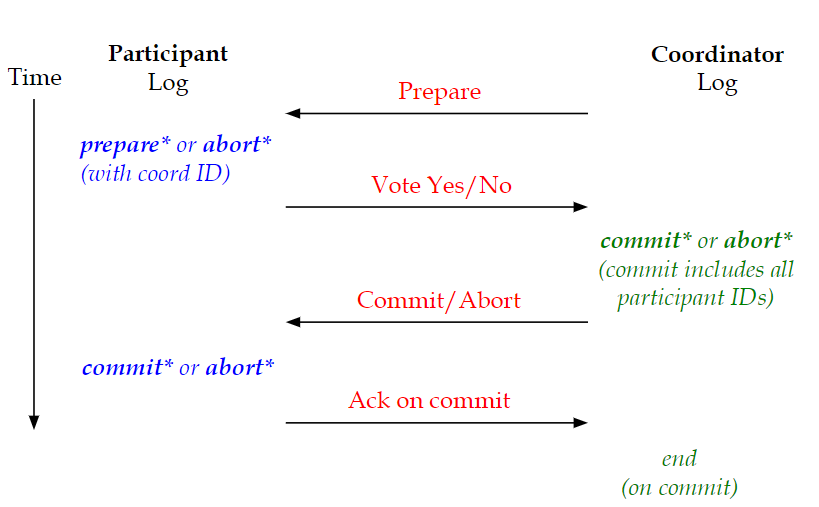
Failure handling
如果协调者发现有参与者发生了故障:
- 如果该参与者还没有参与投票,那就将该事务抛弃。
- 如果已经参与了投票,那就交给恢复操作处理。
如果参与者发现协调者发生故障: - 如果还没有打prepare日志,就单方面拒绝。
- 否则交给恢复过程处理。
分析阶段操作:
- 参与者:检测到prepare log时,将状态调整为commiting,让恢复进程询问协调者当前的状态,如果协调者响应了,就正常处理commit/abort。
- 检测到Commit/Abort log后,将状态做出对于的修改,让恢复进程将状态信息发送给参与者,一旦所有的参与者都确认收到,就写入End记录。
- 标题: Remake | 数据库
- 作者: Zephyr
- 创建于 : 2022-08-02 16:09:52
- 更新于 : 2023-01-26 12:32:06
- 链接: https://faustpromaxpx.github.io/2022/08/02/Database/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。