字节青训整合笔记
啥都听不懂的青训营 摸鱼笔记
Go语言基本特质
协程
协程:用户态,轻量级线程,栈MB级别
线程:内核态,线程中可以运行多个协程,栈KB级别
协程主要通信方式
通过通信共享内存,类似生产者消费者模型
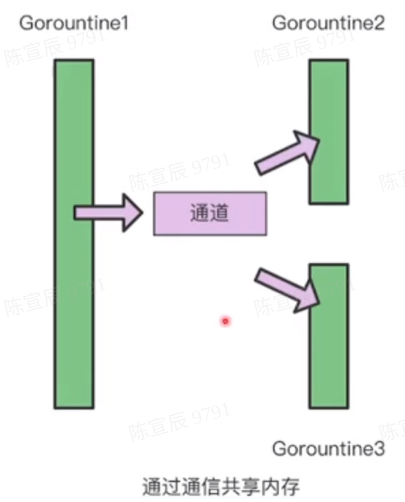
Channel 通道
make(chan 元素类型, [缓冲大小])
无缓冲通道又称为同步通道
适当的缓冲大小可以弥补生产者消费者执行速度不均衡的问题
同步
可使用lock,WaitGroup实现同步。
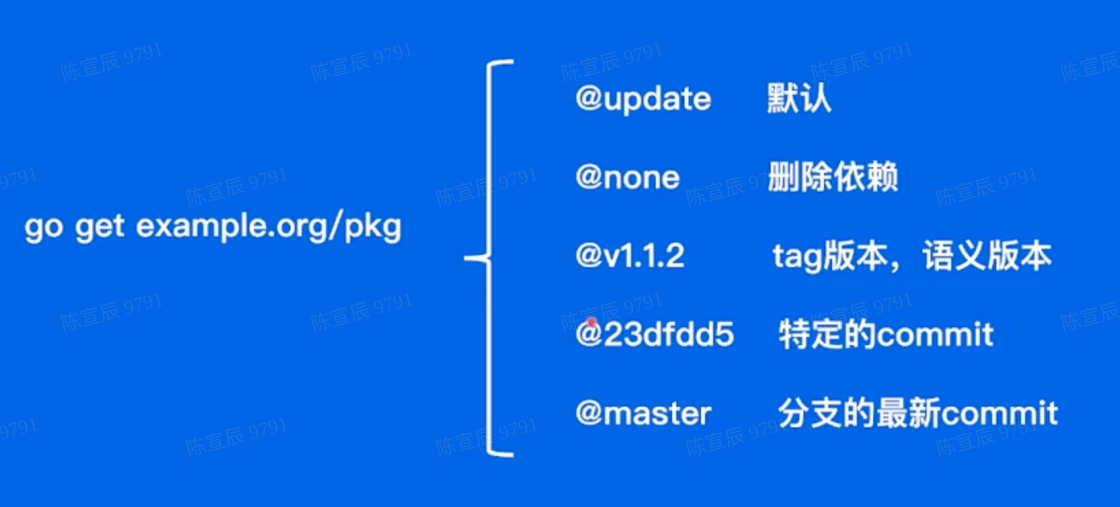
Go的依赖管理
1. GoPath
结构
bin: 项目编译的二进制文件
pkg: 项目编译的中间产物,加速编译
src: 项目源码
项目代码直接依赖于src下的源码
缺陷:无法处理项目代码依赖不同版本的情况
2. GoVendor
项目目录下新增vendor文件,所有依赖包副本形式放在$ProjectRoot/vendor
依赖寻址:有先到vendor下,再到GoPath下
问题:
- 无法控制依赖版本
- 更新项目又可能出现依赖冲突,导致编译出错。
- 本质:仍旧依赖的是源码,无法通过版本分辨
3. Go Module
通过go.mod文件进行版本管理
依赖管理三要素
1. 配置文件,描述依赖 go.mod
1. 中心仓库管理依赖库 Proxy
1. 本地工具 go get/mod
对于所需要的不同版本的依赖,go会采取最低兼容版本算法。
依赖分发-Proxy
在源站与目标之间加一层代理,代理缓存源站中的依赖

单元测试
1. 规则
所有测试文件以_test.go结尾
函数命名:func Testxx(*testing.T)
初始化逻辑放到TestMain中
2. mock
模仿真实对象行为的模拟对象
mock模拟的不是测试对象而是测试对象的依赖
Why?
- (1)提高 A 的测试覆盖率。A 依赖 B,本质上依赖的是 B 的返回结果,也就是说 B 的返回结果会影响 A 的行为。通过 mock B 我们可以构造各种正常和异常的来自 B 的返回结果,从而更充分测试 A 的行为。
- (2)避免 B 的因素从而对 A 产生影响。依赖真实的 B 去测试 A 可能有很多问题:B 的开发没有完成时无法测试 A;B 有阻塞性bug 时无法测试 A;B 的依赖 C 有阻塞性 bug 时无法测试 A;
- (3)提高 A 的测试效率。B 的真实行为可能很慢,而 B 的模拟行为是非常快的,因此可以加快 A 的测试执行速度。
高性能Go语言发行版优化与落地实践
性能优化
业务层优化
- 针对特定场景,具体问题,具体分析
- 容易获得较大性能收益
语言运行时优化
- 解决更通用的性能问题
- 考虑更多场景
- tradeoffs
内存管理
自动内存管理
由程序语言的运行时系统回收动态内存
- 避免手动内存管理,专注于业务逻辑
- 保证内存使用的正确性和安全性
三个任务
- 为新对象分配空间
- 找到存活对象
- 回收死亡对象的内存空间
相关概念
- Mutator:业务线程,分配新对象,修改对象指向关系
- Collector:GC线程,找到存活对象,回收死亡对象的内存空间
- Serial GC: 只有一个Collector,每次进行GC操作时需要暂停程序
- Parallel GC: 支持多个Collector同时回收GC算法
- Concurrent GC:业务代码与垃圾回收同时执行(Collector必须感知对象指向关系的改变)
追踪垃圾回收
对象被回收的条件:指针指向关系不可达的对象
标记根对象:静态变量,全局变量,常量,线程栈等(所有在程序运行时永远存活的对象)
标记:找到可达对象
清理:所有不可达对象(根据对象的生命周期,使用不同的标记和清理策略)
- 将存活对象复制到另外的内存空间
- 将死亡对象的内存标记为“可分配”
- 移动并整理存活对象
分代GC
Intution:很多对象在分配出来后很快就不再使用了
每个对象的年龄:经历过GC的次数
不同年龄的对象处于heap的不同区域
年轻代
常规的对象分配
由于存活对象很少,可以直接复制到其他空间
GC吞吐率高
老年代
对象趋向于一直活着,反复复制开销大
可以采用标记对象的方法。
引用计数
每个对象都有一个与之关联的引用数目
对象存活的条件:当且仅当引用数大于0
优点:
- 内存管理的操作被平摊到程序执行过程中
- 内存管理不需要了解runtime的实现细节
缺点:
- 维护引用计数的开销较大:通过原子操作保证对引用技术操作的原子性和可见性
- 无法回收环形数据结构 (所有对象相互之间会引用,虽然该数据结构已经不可达,但因为其中每个对象的引用数不会降为0,所以无法被回收)
- 内存开销:每个对象都引入的额外内存空间存储引用数目
- 回收内存依然可能引发暂停
Balanced GC
GAB对于Go内存管理来说是个对象
本质:将多个小对象的分配合并成一次对象的分配
利用三个指针标记内存块的起点和终点,以及下一块可用内存的地址
问题:GAB的对象分配方式会导致内存被延迟释放。例如,GAB中仅存活了1个小对象,此时GAB无法释放,但又浪费了大量内存。
解决:当GAB总大小超过一定阈值时,将GAB中存活的对象复制到另外分配的GAB中(用copying GC 的算法管理小对象)
编译优化
编译器的结构
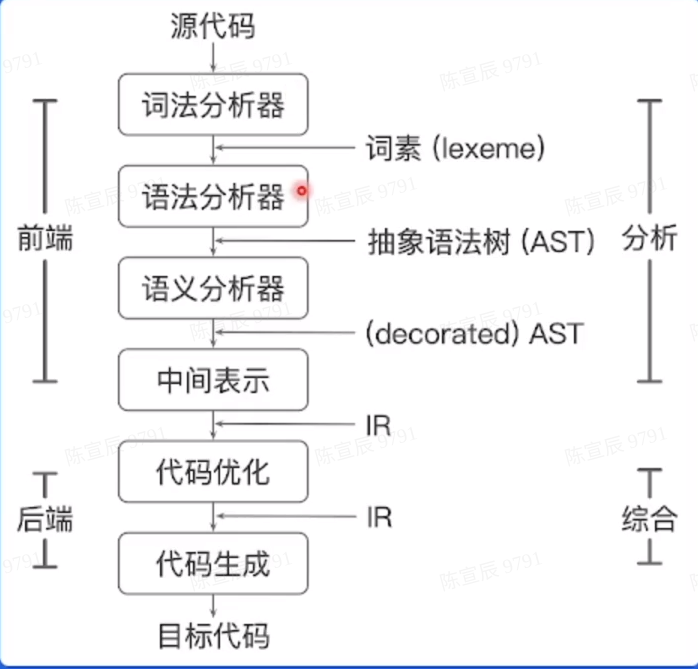
函数内联
将被调用函数的函数体的副本替换到调用位置,同时重写代码以反映参数的绑定
优点:
- 消除函数调用开销,例如传递参数,保存寄存器等
- 将过程间分析转化为过程内分析,帮助其他优化
缺点:
- 函数体变大,(icache)不友好
- 编译生成的Go镜像变大
逃逸分析
分析代码中指针的动态作用域,指针在何处可以被访问
思路:
从对象分配处出发,沿着控制流,观察对象的数据流
若发现指针p在当前作用域s:
作为参数传递给其他函数
传递给全局变量
传递给其他的goroutine
传递给已逃逸的指针指向的对象
即,若该对象可以被外部函数调用,则称其逃逸出s
优化:增加函数的内联,扩大函数边界,使得原本逃逸的对象只能作用在当前作用域。而未逃逸的对象可以在栈上分配,并且无论是分配还是回收都很快,同时也减少了在heap上的分配,减小GC负担。
网络
网络接入 —— 路由
路由不是对称的,根据当前的网络情况,响应包的路径也可能跟请求包不同
路由也不会修改IP地址,在数据包传输过程中,源IP与目的IP均不会发生变化,只会修改MAC地址,同时在发出数据包时不仅要知道目的MAC,还要知道发出的端口。
ARP请求不会跨网段发送,若目的与源不在同一网段,则会先寻找下一跳的MAC地址,利用ARP逐级跳转。
免费ARP
发送一个包含新IP的ARP数据包,提示所有服务器刷新ARP表
- 当网段中新增了一台机器时,可以通过这种方式让其余机器刷新ARP表,而避免在使用时临时刷新。
- 当服务器有新增IP时,可以通过免费ARP检测IP冲突。
PS:Mac地址不能替代IP地址 -> IP地址的存在实际上就是为了解决二层协议(包括Mac)的兼容问题。
SSL/TLS非对称加密
将数据进行加密之后再传输,并且使用的加密算法也进行加密,接收方通过与发送方协商获知所使用的加密算法。
网络提速
对于静态资源,使用CDN缓存
对于动态API,优化网络路径
网络容灾
故障发生->故障感知->自动切换->服务恢复
- 外网容灾

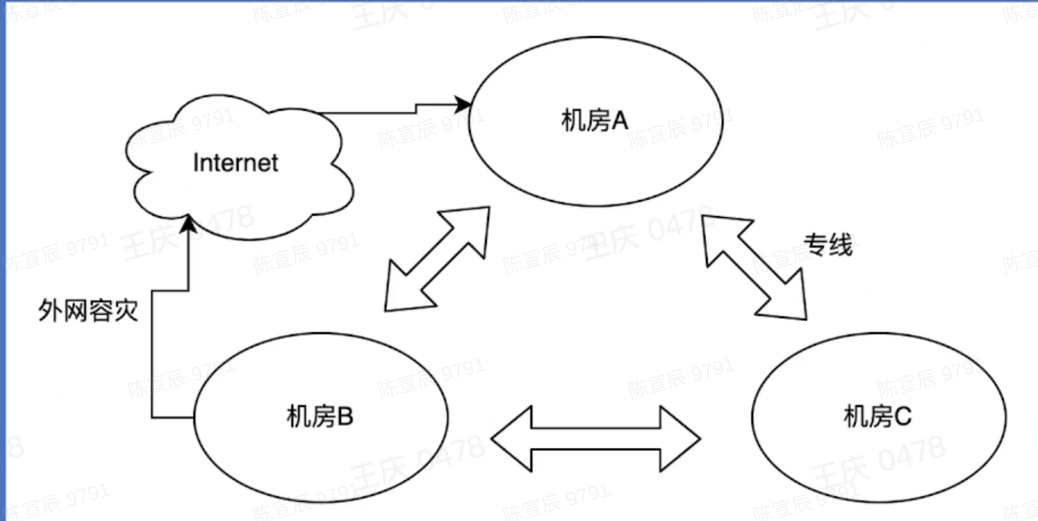
内部专线出现故障后,切换为外网连接
- 降级容灾
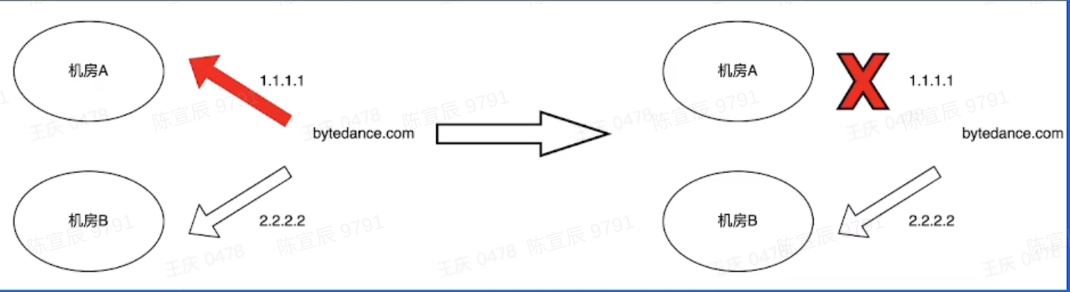
网址会被映射到两个机房,其中一个机房出现问题时,首先进行故障感知,然后判断机房B能否承受住那部分流量,最后才进行切换。
- 缓存
当程序故障后,就用缓存先响应用户请求
DNS
DNS记录类型
- A/AAAA:IP指向记录,前者指向IPv4, 后者指向IPv6
- CNAME:别名记录,配置值为别名或主机名,客户端根据别名继续解析以提取IP地址
- TXT:文本记录,购买证书时需要
- MX:邮件交换记录,用于指向邮件交换服务器
- NS:解析服务器记录,用于指定哪台服务器对于该域名解析
- SOA:起始授权机构记录
HTTP接入协议
加密
对称加密:使用相同的秘钥来加密传输内容,一端加密后,对端收到数据会用相同的秘钥来解密
非对称加密:如果用公钥对数据进行加密,只有用对应的私钥才能解密;如果用私钥对数据进行加密,那么只有用对应的公钥才能解密。
高质量编程与性能调优
编程原则
简单性
消除“多余的复杂性”,以简单清晰的逻辑编写代码
可读性
生产力
编码规范
注释:
注释应该解释代码作用, 适合注释公共符号
注释应该解释代码如何做的,适合注释实现过程
注释应该解释代码实现的原因,适合解释代码的外部因素,提供额外的上下文。
注释应该解释代码什么情况会出错,适合解释代码的限制条件。
公共符号始终需要注释
PS:代码是最好的注释,注释应提供代码未表达出的上下文信息。
变量命名:
- 简洁
- 缩略词全部大写,当其位于变量开头其不需要导出时,全部小写
- 变量与实际使用位置距离越远,需要携带的上下文信息越多
函数命名:
- 函数名不携带包名的上下文信息
- 简短
- 当名为foo的包某个函数返回类型Foo时,可以省略类型信息。
包名:
- 只由小写字母组成。不包含大写字母和下划线等字符
- 简短并包含一定上下文信息
- 不要与标准库同名
控制流程:
- 线性原理,避免嵌套
- 正常代码最小缩进
性能优化
Go提供benchmark工具进行基准性能测试
go test -bench=. -benchmen性能优化建议
预分配
尽量在make阶段确定切片/对象大小
slice进行扩容时会在已有切片基础上创建切片,不会创建新的底层数组。
场景
- 原切片较大,代码在原切片基础上新建小切片
- 原底层数组在内存中有引用,得不到释放
此时可以使用copy代替re-slice
空结构体
使用空结构体节省内存
空结构体struct{}实例不占据任何的内存空间
使用场景:
- 节省资源
- 空结构体本身具备很强的语义,可以作为占位符使用
atomic
锁是通过操作系统来实现,属于系统调用
atomic操作通过硬件实现,效率更高
sync.Mutex应该用于保护一段逻辑,而不仅仅是用于保护一个变量
架构
架构的定义
- 是有关软件整体结构与组件的抽象描述
- 用于指导软件系统各个方面的设计
架构的演进
单机
把所有功能都实现在一个进程里,并部署在一台机器上
优点:简单
缺点:能提供的服务有限,运维需要停服。
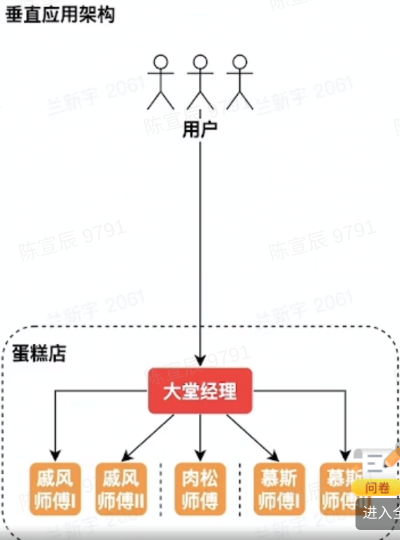
单体、垂直应用 | 垂直切分
单体架构:分布式部署
垂直应用架构:按应用垂直切分的单体
优点:水平扩容,运维不需要停服
缺点:职责太多,开发效率不高。爆炸半径大(个体出现问题,容易导致整条链停摆)
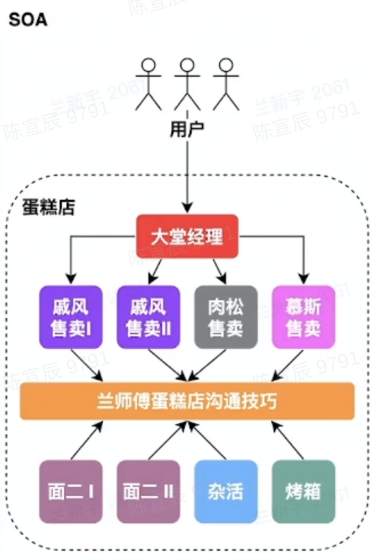
SOA
service-oriented architecture
- 将应用的不同功能单元抽象为服务
- 定义服务之间的通信标准(核心要点)
微服务
SOA的去中心化演进方向
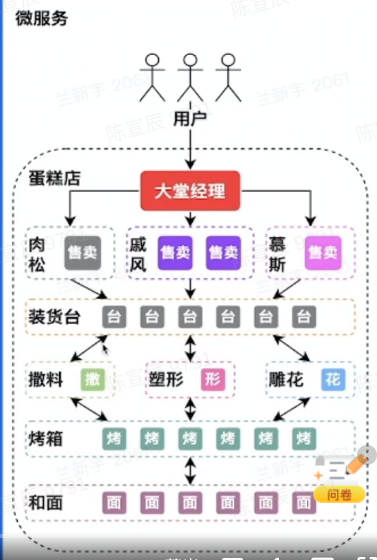
问题:
- 数据一致性
- 高可用,不同服务之间如何高效交互
- 治理,如何容灾
- 解耦 vs 运维 收益是否大于提高的运维成本
- 标题: 字节青训整合笔记
- 作者: Zephyr
- 创建于 : 2022-06-30 03:19:53
- 更新于 : 2023-01-26 12:31:58
- 链接: https://faustpromaxpx.github.io/2022/06/30/coroutine/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。